In this article I document, step by step, the construction of the web server, so you can get a feel for how it is built from a blank slate, the design and implementation decisions (good or bad) and the overall process. The first step of process is to get an HttpListener class working. Then we add some logging. Then create a basic structure for our web application. Next I implement a simple mechanism for routing verbs and paths to handlers, and deal with authenticaion and session expiration, and do some AJAX Queries.
Introduction
Mainly for the fun of it, I decided to look into what's involved in writing my own web server. I quickly became enthralled with the idea and the fascinating things I was discovering about browsers, compliance with browser expectations in the responses, and the sheer pleasure of writing a lean and mean web server. So, this article (as requested a few weeks ago by several people) describes the process. At this point, the implementation supports:
- Routing
- Session Manager
- Authorization
- Expired Sessions
Because the web server is so lightweight, I found it completely unnecessary to do anything complicated like implementing plug-ins for the actual application. There's three core files:
- Listener.cs - Listens and responds to connections using HttpListener
- Router.cs - Manages routing
- SessionManager.cs - Manages connection sessions state
A Soapbox Moment (or several)
I think it's important to state what this web server is not. What you won't find (and you may disagree with my severe criticisms, but this what I've learned over the last few years of web development):
- Anything ORM. ORM should absolutely never be part of a web server
- Anything MVC. The whole MVC concept for web apps is an often unnecessary architecture designed to make Ruby on Rails developers comfortable with Microsoft technologies.
- No runtime compilation of web pages or custom syntaxes for parsing "enhanced" HTML files. Given modern jQuery-based controls like jqwidgets and employing JSON and AJAX, the need for turning an HTML file into something imperative by embedding C# (or other language) elements, well, that just isn't necessary. It:
- slows down serving the page
- smears the logic that determines view state into the view where usually shouldn't belong
- and if it's necessary to write a complex rendering, this is better done in a decent fluid-like architecture rather than syntaxes that further obfuscate the already arcane syntax of HTML and CSS.
- Attributes - I've said it since I started working with C#: attributes are great for giving a serializer hints for how to serialize fields or properties, other than that, they mostly promote bad design -- design which would be much better served with good object oriented design. For example, my routes are implemented by a
Route base class and AuthenticatedRoute child class. If you want role-based authentication, it becomes a derived class rather than an attribute that decorates often empty controller functions and that requires hoops to go through to implement something different than what the framework designers decided would be the right implementation. Throw that all away, because it never works the way you want it, and it adds more performance bloat constantly using reflection to check "oh, am I authorized", "oh, do I have the right role for this?" Again, another example of horrid design. - No IIS. More unnecessary bloat and configuration complexity that isn't needed.
The ironic thing (and this is the last I'll say of it while standing on my soapbox) is that, having implemented my own web server, I've come to realize how much technologies like MVC Razor and Ruby on Rails (to pick two) get in the way of the business of serving web pages and giving the programmer control over how to render non-static content. With a simple web server, I find myself focusing much more on the client-side JavaScript, HTML, and components, where the only attention I have to pay to the server-side process is the PUT handlers and the occasional AJAX request. The baggage created by MVC, arcane routing syntaxes, attributes decorating unnecessary controller functions--well, the whole state of affairs of writing a web application is rather dismal, in my opinion.
About the Source Code Repository
The source code is hosted on GitHub:
git clone https:
About the Process of this Article
Rather than just showing you the final web server, I think it's much more interesting to document, step by step, the construction of the web server, so you can get a feel for how it is built from a blank slate, the design and implementation decisions (good or bad) and the overall process. I hope you, the reader, enjoy this approach.
Step 1 - HttpListener
The first step of process is to get an HttpListener class working. I opted to go this route rather than the lower level socket route because HttpListener provides a lot of useful services, such as decoding the HTML request. I've read that it's not as performant as going the socket route, but I'm not overly concerned with a little performance reduction.
The web server is implemented as a library. There is a console application for the specific web application executable. For this first step, the web server needs:
using System.Net;
using System.Net.Sockets;
using System.Threading;
Because a web server is primarily stateless (except for session objects) most of behaviors can be implemented as static singletons.
namespace Clifton.WebServer
{
public static class Server
{
private static HttpListener listener;
...
We're going to make the initial assumption that we're connecting to the server on an intranet, so we obtain the IP's of our local host:
private static List<IPAddress> GetLocalHostIPs()
{
IPHostEntry host;
host = Dns.GetHostEntry(Dns.GetHostName());
List<IPAddress> ret = host.AddressList.Where(ip => ip.AddressFamily == AddressFamily.InterNetwork).ToList();
return ret;
}
We then instantiate the HttpListener and add the localhost prefixes:
private static HttpListener InitializeListener(List<IPAddress> localhostIPs)
{
HttpListener listener = new HttpListener();
listener.Prefixes.Add("http://localhost/");
localhostIPs.ForEach(ip =>
{
Console.WriteLine("Listening on IP " + "http://" + ip.ToString() + "/");
listener.Prefixes.Add("http://" + ip.ToString() + "/");
});
return listener;
}
You will probably have more than one localhost IP. For example, my laptop has an IP for both the ethernet and wireless "ports."
Borrowing a concept from Sacha's A Simple REST Framework, we'll set up a semaphore that waits for a specified number of simultaneously allowed connections:
public static int maxSimultaneousConnections = 20;
private static Semaphore sem = new Semaphore(maxSimultaneousConnections, maxSimultaneousConnections);
This is implemented in a worker thread, which is invoked with Task.Run:
private static void Start(HttpListener listener)
{
listener.Start();
Task.Run(() => RunServer(listener));
}
private static void RunServer(HttpListener listener)
{
while (true)
{
sem.WaitOne();
StartConnectionListener(listener);
}
}
Lastly, we implement the connection listener as an awaitable asynchronous process:
private static async void StartConnectionListener(HttpListener listener)
{
HttpListenerContext context = await listener.GetContextAsync();
sem.Release();
}
So, let's do something:
string response = "Hello Browser!";
byte[] encoded = Encoding.UTF8.GetBytes(response);
context.Response.ContentLength64 = encoded.Length;
context.Response.OutputStream.Write(encoded, 0, encoded.Length);
context.Response.OutputStream.Close();
And, we need a public Start method:
public static void Start()
{
List<IPAddress> localHostIPs = GetLocalHostIPs();
HttpListener listener = InitializeListener(localHostIPs);
Start(listener);
}
Now in our console app, we can start up the server:
using System;
using Clifton.WebServer;
namespace ConsoleWebServer
{
class Program
{
static void Main(string[] args)
{
Server.Start();
Console.ReadLine();
}
}
}
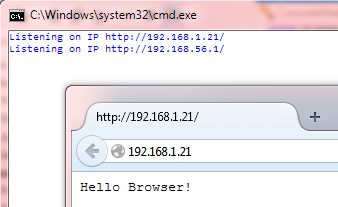
and away we go:

Always Inspect the Browser's Web Console Window
The browser's web console window is your friend - it will tell you all the things you are doing wrong! For example, in our test case above, we discover:
Here we learn that we need to take care of the encoding, which is done in the HTML:
string response = "<html><head><meta http-equiv='content-type' content='text/html; charset=utf-8'/>
</head>Hello Browser!</html>";
As this is just an example, we'll leave it at that for now. Later we'll learn more things we're doing wrong!
Step 2 - Logging
First, let's add some logging, as logging is really useful to see what kind of requests are being made of our web server:
Log(context.Request);
public static void Log(HttpListenerRequest request)
{
Console.WriteLine(request.RemoteEndPoint + " " + request.HttpMethod + " /" + request.Url.AbsoluteUri.RightOf('/', 3));
}
You can also use remote loggers, like PaperTrailApp, which I've written about here.
We add the Log call right after releasing the semaphore:
Log(context.Request);
What we Notice After Adding the Logger
Once we add the logging, we notice immediately that the browser not only requests the page at the default page, but it's also asking for favicon.ico!
Well, we need to something about that!
Step 3 - Serving Content: Default Routing
Obviously, we don't want to code our web pages as strings in C#. So, let's create a basic structure for our web application. This is completely arbitrary, but what I've chosen as a structure is that everything will derive from the folder "Website". Under "Website", we find the following folders:
- Pages: root of all pages
- CSS: contains all .css and related files
- Scripts: contains all .js files
- Images: contains all image files
To handle some basic functionality, we need the beginnings of a router. Our first cut will do nothing else than respond with files found in the "Webiste" folder and sub-folders as determined by the URL path and the request extension. We first extract some information from the URL request:
HttpListenerRequest request = context.Request;
string path = request.RawUrl.LeftOf("?");
string verb = request.HttpMethod;
string parms = request.RawUrl.RightOf("?");
Dictionary<string, string> kvParams = GetKeyValues(parms);
We can now pass this information to the router:
router.Route(verb, path, kvParams);
Even though it could be static, there are some potential benefits to making the router an actual instance, so we initialize it in the Server class:
private static Router router = new Router();
Another nitpicky detail is the actual website path. Because I'm running the console program out of a bin\debug folder, the website path is actually "..\..\Website". Here's a clumsy way of getting this path:
public static string GetWebsitePath()
{
string websitePath = Assembly.GetExecutingAssembly().Location;
websitePath = websitePath.LeftOfRightmostOf("\\").LeftOfRightmostOf("\\").LeftOfRightmostOf("\\") + "\\Website";
return websitePath;
}
A little refactoring is need to We pass this in to the web server, which configures the router:
public static void Start(string websitePath)
{
router.WebsitePath = websitePath;
...
Since I don't particularly like switch statements, we'll initialize a map of known extensions and their loader locations. Consider how different functions could be used to load the content from, say, a database.
public class Router
{
public string WebsitePath { get; set; }
private Dictionary<string, ExtensionInfo> extFolderMap;
public Router()
{
extFolderMap = new Dictionary<string, ExtensionInfo>()
{
{"ico", new ExtensionInfo() {Loader=ImageLoader, ContentType="image/ico"}},
{"png", new ExtensionInfo() {Loader=ImageLoader, ContentType="image/png"}},
{"jpg", new ExtensionInfo() {Loader=ImageLoader, ContentType="image/jpg"}},
{"gif", new ExtensionInfo() {Loader=ImageLoader, ContentType="image/gif"}},
{"bmp", new ExtensionInfo() {Loader=ImageLoader, ContentType="image/bmp"}},
{"html", new ExtensionInfo() {Loader=PageLoader, ContentType="text/html"}},
{"css", new ExtensionInfo() {Loader=FileLoader, ContentType="text/css"}},
{"js", new ExtensionInfo() {Loader=FileLoader, ContentType="text/javascript"}},
{"", new ExtensionInfo() {Loader=PageLoader, ContentType="text/html"}},
};
}
....
Notice how we also handle the "no extension" case, which we implement as assuming that the content will be an HTML page.
Also notice that we set the content type. If we don't do this, we get a warning in the web console that content is assumed to be of a particular type.
Finally, notice that we're indicating a function for performing the actual loading.
Image Loader
private ResponsePacket ImageLoader(string fullPath, string ext, ExtensionInfo extInfo)
{
FileStream fStream = new FileStream(fullPath, FileMode.Open, FileAccess.Read);
BinaryReader br = new BinaryReader(fStream);
ResponsePacket ret = new ResponsePacket() { Data = br.ReadBytes((int)fStream.Length), ContentType = extInfo.ContentType };
br.Close();
fStream.Close();
return ret;
}
File Loader
private ResponsePacket FileLoader(string fullPath, string ext, ExtensionInfo extInfo)
{
string text = File.ReadAllText(fullPath);
ResponsePacket ret = new ResponsePacket() { Data = Encoding.UTF8.GetBytes(text), ContentType = extInfo.ContentType, Encoding = Encoding.UTF8 };
return ret;
}
Page Loader
The page loader has to do some fancy footwork to handle options like:
- foo.com
- foo.com\index
- foo.com\index.html
All of these combinations end up load Pages\index.html.
private ResponsePacket PageLoader(string fullPath, string ext, ExtensionInfo extInfo)
{
ResponsePacket ret = new ResponsePacket();
if (fullPath == WebsitePath)
{
ret = Route(GET, "/index.html", null);
}
else
{
if (String.IsNullOrEmpty(ext))
{
fullPath = fullPath + ".html";
}
fullPath = WebsitePath + "\\Pages" + fullPath.RightOf(WebsitePath);
ret = FileLoader(fullPath, ext, extInfo);
}
return ret;
}
We have a couple helper classes:
public class ResponsePacket
{
public string Redirect { get; set; }
public byte[] Data { get; set; }
public string ContentType { get; set; }
public Encoding Encoding { get; set; }
}
internal class ExtensionInfo
{
public string ContentType { get; set; }
public Func<string, string, string, ExtensionInfo, ResponsePacket> Loader { get; set; }
}
And after putting it all together, we have the beginnings of a router, which now returns content located in files.
public ResponsePacket Route(string verb, string path, Dictionary<string, string> kvParams)
{
string ext = path.RightOf('.');
ExtensionInfo extInfo;
ResponsePacket ret = null;
if (extFolderMap.TryGetValue(ext, out extInfo))
{
string fullPath = Path.Combine(WebsitePath, path);
ret = extInfo.Loader(fullPath, ext, extInfo);
}
return ret;
}
We need one final refactoring -- removing our test response and replacing it with the content returned by the router:
private static void Respond(HttpListenerResponse response, ResponsePacket resp)
{
response.ContentType = resp.ContentType;
response.ContentLength64 = resp.Data.Length;
response.OutputStream.Write(resp.Data, 0, resp.Data.Length);
response.ContentEncoding = resp.Encoding;
response.StatusCode = (int)HttpStatusCode.OK;
response.OutputStream.Close();
}
This is bare-bones implementation for now.
We can see this in action. Here's some HTML:
<!DOCTYPE html>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8" />
<script type="text/javascript" src="/Scripts/jquery-1.11.2.min.js"></script>
<link type="text/css" rel="Stylesheet" href="/CSS/demo.css"/>
<title>Button Click Demo</title>
<script type="text/javascript">
$(document).ready(function () {
$("#me").click(function () {
alert("I've been clicked!");
});
});
</script>
</head>
<body>
<div class="center-inner top-margin-50">
<input class="button" type="button" value="Click Me" id="me"/>
</div>
</body>
</html>
You can see the website structure:
And our little demo page works!
You can see several things going on here:
- Yes indeed, favicon.ico is being loaded (it's a palm tree, if you were wondering)
- The page is of course being loaded
- The styling is working
- The JQuery script is working
This is all fine and dandy, but:
- Unknown extensions are not handled
- Missing content is not handled
- Errors loading content are not handled
- The verb is always assumed to be "get"
- The application isn't given any option to manipulate the content (particularly the HTML) after it's been loaded
- You can't override the routing
- There's not concept of authorized content
- There's no session duration considered
- There's no exception handling
- Redirects are not handled
These are all issues that we need to address, however, we can at this point create some pages with CSS and Javascript:, so, even though there's a lot of things to still work on, we do at this point have a lot working!
One of the things revealed here is how the actual location of the content "file" can be completely spoofed by the server. In the above code, I put all the HTML content under the folder Pages, thus spoofing the root location. We could do other things -- load data from a database, communicate with another server, generate the page dynamically from data...these are all features will explore as we move beyond default content loading.
Step 4 - The Devil is in the Details
Let's start dealing with the issues mentioned above.
Error Pages
We'll add several error pages, even though we're not using them all at the moment:
- Expired session
- Not authorized
- Page not found
- Server error
- Unknown type
Now, you may wonder why the server knows things about expired sessions and authorization failures. Well, because it makes sense -- these errors are integral to the routing, but the error state is determined by the web application (not the server.) All the server does is query the web application for the state. More on this later.
We'd like the application to be determine where these pages are for the given error, so we'll add an enum to the server:
public enum ServerError
{
OK,
ExpiredSession,
NotAuthorized,
FileNotFound,
PageNotFound,
ServerError,
UnknownType,
}
We can now begin to handle errors (without throwing exceptions). First off is an unknown extension:
if (extFolderMap.TryGetValue(ext, out extInfo))
{
...
}
else
{
ret = new ResponsePacket() { Error = Server.ServerError.UnknownType };
}
and so forth. We'll use a callback that the web application can provide for handling errors. This is in the form of the page to which the user should be redirected.
We then refactor our code to get, from the application, the page to display on error:
ResponsePacket resp = router.Route(verb, path, kvParams);
if (resp.Error != ServerError.OK)
{
resp = router.Route("get", onError(resp.Error), null);
}
Respond(context.Response, resp);
and implement a straight forward error handler in the application:
public static string ErrorHandler(Server.ServerError error)
{
string ret = null;
switch (error)
{
case Server.ServerError.ExpiredSession:
ret= "/ErrorPages/expiredSession.html";
break;
case Server.ServerError.FileNotFound:
ret = "/ErrorPages/fileNotFound.html";
break;
case Server.ServerError.NotAuthorized:
ret = "/ErrorPages/notAuthorized.html";
break;
case Server.ServerError.PageNotFound:
ret = "/ErrorPages/pageNotFound.html";
break;
case Server.ServerError.ServerError:
ret = "/ErrorPages/serverError.html";
break;
case Server.ServerError.UnknownType:
ret = "/ErrorPages/unknownType.html";
break;
}
return ret;
}
Of course, we have to initialize the error handler:
Server.onError = ErrorHandler;
We can now test a few things out. Of course, your application may want some more sophisticated messages!
Unknown Type Error
Page Not Found
File Not Found
Redirects
You'll note that the URL in the above error messages hasn't changed to reflect the page. This is because we don't have response redirect working. Time to fix that:
We assume that the error handler will always redirect us to a different page, so we change how we handle the response. Rather than getting a new ResponsePacket and sending that content back to the browser, we simply set the Redirect property to the page the web application wants us to go to. This becomes, by the way, a universal redirect mechanism.)
if (resp.Error != ServerError.OK)
{
resp.Redirect = onError(resp.Error);
}
and we do a little refactoring in the Resond method:
private static void Respond(HttpListenerRequest request, HttpListenerResponse response, ResponsePacket resp)
{
if (String.IsNullOrEmpty(resp.Redirect))
{
response.ContentType = resp.ContentType;
response.ContentLength64 = resp.Data.Length;
response.OutputStream.Write(resp.Data, 0, resp.Data.Length);
response.ContentEncoding = resp.Encoding;
response.StatusCode = (int)HttpStatusCode.OK;
}
else
{
response.StatusCode = (int)HttpStatusCode.Redirect;
response.Redirect("http://" + request.UserHostAddress + resp.Redirect);
}
response.OutputStream.Close();
}
By the way, it's very important to close the output stream. If you don't, the browser can be left hanging, waiting for data.
Notice that since we're handling errors with redirects, the only two possible status codes our web server can respond with is OK and Redirect.
Now our redirecting is working:
Exception Handling
We use the same redirect mechanism to catch actual exceptions by wrapping the GetContextAsync continuation in a try-catch block:
catch(Exception ex)
{
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
resp = new ResponsePacket() { Redirect = onError(ServerError.ServerError) };
}
Here's what a simulated error looks like:
Step 5 - Review and Tackle More Issues
Where are we?
Unknown extensions are not handledMissing content is not handledErrors loading content are not handled- The verb is always assumed to be "get"
- The application isn't given any option to manipulate the content (particularly the HTML) after it's been loaded
- You can't override the routing
- There's not concept of authorized content
- There's no session duration considered
There's no exception handlingRedirects are not handled
Let's deal with verbs next, particularly POST verbs. This will allow us to tackle the next three live bullet items.
Verbs
There are several verbs that can accompany an HTTP request:
- OPTIONS
- GET
- HEAD
- POST
- PUT
- DELETE
- TRACE
- CONNECT
Essentially, the web server doesn't really care about the verb -- all the verb does is provide additional information as to what handler to invoke for the response. Here we finally get to a topic I've avoided so far -- controllers. Rather than the web server having any cognizance of a Model-View-Controller pattern and/or enforcing such pattern on the web application developer, the web server I've implemented provides a simple mechanism for routing verbs and paths to handlers. That's all it needs to do. The handler, in turn, determines whether the browser should be redirected to a different page or stay on the current page. Behind the scenes, the handler can do other things, but from the perspective of the web server, that's all that the web server cares about.
Routes
We'll begin by adding a basic router. This consists of a Route class:
public class Route
{
public string Verb { get; set; }
public string Path { get; set; }
public Func<Dictionary<string,string>, string> Action { get; set; }
}
Notice the Action property, which is a callback function that passes in the URL parameters (we'll deal with post parameters in a bit) and expects an "optional" redirect URL.
We add a simple method to add routes to a route table:
public void AddRoute(Route route)
{
routes.Add(route);
}
Now we can implement calling application specific handlers, which is a refactor of the Route method:
public ResponsePacket Route(string verb, string path, Dictionary<string, string> kvParams)
{
string ext = path.RightOfRightmostOf('.');
ExtensionInfo extInfo;
ResponsePacket ret = null;
verb = verb.ToLower();
if (extFolderMap.TryGetValue(ext, out extInfo))
{
string wpath = path.Substring(1).Replace('/', '\\');
string fullPath = Path.Combine(WebsitePath, wpath);
Route route = routes.SingleOrDefault(r => verb == r.Verb.ToLower() && path == r.Path);
if (route != null)
{
string redirect = route.Action(kvParams);
if (String.IsNullOrEmpty(redirect))
{
ret = extInfo.Loader(fullPath, ext, extInfo);
}
else
{
ret = new ResponsePacket() { Redirect = redirect };
}
}
else
{
ret = extInfo.Loader(fullPath, ext, extInfo);
}
}
else
{
ret = new ResponsePacket() { Error = Server.ServerError.UnknownType };
}
return ret;
}
Now let's modify our demo page to make a POST call to the server when we click the button, and we'll redirect to a different page in our handler. Yes, I know this could be handled entirely in the Javascript, but we're demonstrating verb-path handlers here, so we'll implement this behavior on the server-side.
Let's also add processing the input stream of the request into key-value pairs as well, and add logging of the parameters (both in the URL and any parameters in the input stream) that is part of the request:
private static async void StartConnectionListener(HttpListener listener)
{
...
Dictionary<string, string> kvParams = GetKeyValues(parms);
string data = new StreamReader(context.Request.InputStream, context.Request.ContentEncoding).ReadToEnd();
GetKeyValues(data, kvParams);
Log(kvParams);
...
}
private static Dictionary<string, string> GetKeyValues(string data, Dictionary<string, string> kv = null)
{
kv.IfNull(() => kv = new Dictionary<string, string>());
data.If(d => d.Length > 0, (d) => d.Split('&').ForEach(keyValue => kv[keyValue.LeftOf('=')] = keyValue.RightOf('=')));
return kv;
}
private static void Log(Dictionary<string, string> kv)
{
kv.ForEach(kvp=>Console.WriteLine(kvp.Key+" : "+kvp.Value));
}
It may be a bad practice to combine URL parameters and postback parameters into a single key-value pair collection, but we'll go with this "simpler" implementation for now.
We create a new HTML page /demo/redirect:
<!DOCTYPE html>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8" />
<title>Redirect Demo</title>
<link type="text/css" rel="Stylesheet" href="/CSS/demo.css"/>
</head>
<body>
<form name="myform" action="/demo/redirect" method="post">
<div class="center-inner top-margin-50">
<input type="submit" class="button" value="Redirect Me" id='redirect' name="redirectButton" />
</div>
</form>
</body>
</html>
And, without doing anything further, let's look at the trace log and the behavior when we click on the button:
First we see the GET verb as the page loads, then, clicking on the button, we see the POST with the parameters. The fun thing about writing your own web server is you really get a deeper sense of what is happening behind the scenes, something that is important for people who are new to web development. Note the following in relation to the HTML:
- The method verb must be in lowercase. If you use "POST", Visual Studio's IDE warns that this is an unrecognized HTML5 verb.
- Ironically, the verb in the HttpListenerRequest.HttpMethod property is in uppercase!
- Note how the action path is the HttpListenerRequest.Url.AbsoluteUri
- Note the way the post data is packaged. The "key" is the HTML element's name and the "value" is the HTML element's value. Observe how whitespaces in the value have been replaced with '+'.
Now let's register a handler for this verb and path:
static void Main(string[] args)
{
string websitePath = GetWebsitePath();
Server.onError = ErrorHandler;
Server.AddRoute(new Route() { Verb = Router.POST, Path = "/demo/redirect", Action = RedirectMe });
Server.Start(websitePath);
Console.ReadLine();
}
public static string RedirectMe(Dictionary<string, string> parms)
{
return "/demo/clicked";
}
And now, when we click the button, we're redirected:
That was easy.
With a minimal amount of refactoring, we've take care of these three issues:
- The verb is always assumed to be "get"
- The application isn't given any option to manipulate the content (particularly the HTML) after it's been loaded
- You can't override the routing
Step 6 - Authentication and Session Expiration
In step 5 above, I implemented a very basic route handler. What we'd like is something a little more sophisticated that can handle very common tasks:
- making sure the user is authorized to view the page
- checking if the session has expired
We'll refactor the handler callbacks above to utilize a Routing class from which we can provide some built-in behaviors as well as allowing the web application developer to replace and/or add their own additional behaviors, such as role-based authentication.
Session Management
First, let's add a basic Session and SessionManager class:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net;
using System.Text;
using System.Threading.Tasks;
using Clifton.ExtensionMethods;
namespace Clifton.WebServer
{
public class Session
{
public DateTime LastConnection { get; set; }
public bool Authorized { get; set; }
public Dictionary<string, string> Objects { get; set; }
public Session()
{
Objects = new Dictionary<string, string>();
UpdateLastConnectionTime();
}
public void UpdateLastConnectionTime()
{
LastConnection = DateTime.Now;
}
public bool IsExpired(int expirationInSeconds)
{
return (DateTime.Now - LastConnection).TotalSeconds > expirationInSeconds;
}
}
public class SessionManager
{
protected Dictionary<IPAddress, Session> sessionMap = new Dictionary<IPAddress, Session>();
public SessionManager()
{
sessionMap = new Dictionary<IPAddress, Session>();
}
public Session GetSession(IPEndPoint remoteEndPoint)
{
Session session = sessionMap.CreateOrGet(remoteEndPoint.Address);
return session;
}
}
}
The SessionManager manages Session instances associated with the client's endpoint IP. Note the todo--that we need some way of removing sessions at some point, otherwise this list will just keep growing! The Session class contains a couple useful properties for managing the last connection date/time as well as whether the user has been authorized (logged in, whatever) to view "authorized" pages. We also provide a key-value pair dictionary for the web application to persist "objects" associated with keys. Basic, but functional.
Now, in our listener continuation, we can get the session associated with the endpoint IP:
private static async void StartConnectionListener(HttpListener listener)
{
ResponsePacket resp = null;
HttpListenerContext context = await listener.GetContextAsync();
Session session = sessionManager.GetSession(context.Request.RemoteEndPoint);
...
resp = router.Route(verb, path, kvParams);
session.UpdateLastConnectionTime();
That was quite easy! Note how we're updating the last connection time after giving the router (and our handlers) the option to first inspect the last session state.
Because session expiration is intimately associated with authorization, we expect that when a session expires, the Authorized flag will be cleared.
Anonymous vs. Authenticated Routes
Now let's add some built-in functionality for checking authorization and session expiration. We'll add three classes to our server that the application can use:
- AnonymousRouteHandler
- AuthenticatedRouteHandler
- AuthenticatedExpirableRouteHandler
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Clifton.WebServer
{
public abstract class RouteHandler
{
protected Func<Session, Dictionary<string, string>, string> handler;
public RouteHandler(Func<Session, Dictionary<string, string>, string> handler)
{
this.handler = handler;
}
public abstract string Handle(Session session, Dictionary<string, string> parms);
}
public class AnonymousRouteHandler : RouteHandler
{
public AnonymousRouteHandler(Func<Session, Dictionary<string, string>, string> handler)
: base(handler)
{
}
public override string Handle(Session session, Dictionary<string, string> parms)
{
return handler(session, parms);
}
}
public class AuthenticatedRouteHandler : RouteHandler
{
public AuthenticatedRouteHandler(Func<Session, Dictionary<string, string>, string> handler)
: base(handler)
{
}
public override string Handle(Session session, Dictionary<string, string> parms)
{
string ret;
if (session.Authorized)
{
ret = handler(session, parms);
}
else
{
ret = Server.onError(Server.ServerError.NotAuthorized);
}
return ret;
}
}
public class AuthenticatedExpirableRouteHandler : AuthenticatedRouteHandler
{
public AuthenticatedExpirableRouteHandler(Func<Session, Dictionary<string, string>, string> handler)
: base(handler)
{
}
public override string Handle(Session session, Dictionary<string, string> parms)
{
string ret;
if (session.IsExpired(Server.expirationTimeSeconds))
{
session.Authorized = false;
ret = Server.onError(Server.ServerError.ExpiredSession);
}
else
{
ret = base.Handle(session, parms);
}
return ret;
}
}
}
Notice that we also now pass the session instance to the handler. Convenient!
Next, we refactor the web application routing table to use the RouteHandler derived classes. Our Route class is refactored:
public class Route
{
public string Verb { get; set; }
public string Path { get; set; }
public RouteHandler Handler { get; set; }
}
The session is now passed in to the router and handed over to the route handler:
public ResponsePacket Route(Session session, string verb, string path, Dictionary<string, string> kvParams)
{
...
string redirect = route.Handler.Handle(session, kvParams);
...
Now we just need to update our web application by specifying the type of handler, for example:
Server.AddRoute(new Route() { Verb = Router.POST, Path = "/demo/redirect", Handler=new AnonymousRouteHandler(RedirectMe) });
and of course, our handler now receives the session instance:
public static string RedirectMe(Session session, Dictionary<string, string> parms)
{
return "/demo/clicked";
}
Let's create a route that requires authorization but the authorization flag is not set in the session:
Server.AddRoute(new Route()
{
Verb = Router.POST,
Path = "/demo/redirect",
Handler=new AuthenticatedRouteHandler(RedirectMe)
});
We'll click on the "Redirect Me" button, and note that we get the "not authorized" page:
We'll do the same thing to test the expiration logic:
Server.AddRoute(new Route()
{
Verb = Router.POST,
Path = "/demo/redirect",
Handler=new AuthenticatedExpirableRouteHandler(RedirectMe)
});
and after waiting 60 seconds (configurable in the Server) on the "Redirect Me" page:
While building a website, I find that authentication/expiration often gets in the way, so I like to spoof the authentication. We can do that by implementing onRequest, which the server calls if it exists:
public static Action<Session, HttpListenerContext> onRequest;
...
HttpListenerContext context = await listener.GetContextAsync();
Session session = sessionManager.GetSession(context.Request.RemoteEndPoint);
onRequest.IfNotNull(r => r(session, context));
and we can implement our "always authorized and never expiring" session this way:
static void Main(string[] args)
{
string websitePath = GetWebsitePath();
Server.onError = ErrorHandler;
Server.onRequest = (session, context) =>
{
session.Authorized = true;
session.UpdateLastConnectionTime();
};
Step 7 - AJAX Queries
Let's look at an AJAX callback to see if there's anything we need to do to handle that. We'll put together an HTML page with a simple AJAX jQuery script:
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8" />
<title>AJAX Demo</title>
<script type="text/javascript" src="/Scripts/jquery-1.11.2.min.js"></script>
<link type="text/css" rel="Stylesheet" href="/CSS/demo.css"/>
<script type="text/javascript">
$(document).ready(function () {
$("#me").click(function () {
$.ajax({
url: this.href,
datatype: "json",
async: true,
cache: false,
type: "put",
data: {
number: 5
},
success: function(data, status)
{
alert(data);
}
});
});
});
</script>
</head>
<body>
<div class="center-inner top-margin-50">
<input class="button" type="button" value="AJAX!" id="me"/>
</div>
</body>
</html>
We can see the request being made, but since we don't have a specific handler for this request, we see the server responding with the contents of the page, which is expected.
So let's register a route handler:
Server.AddRoute(new Route()
{
Verb = Router.PUT,
Path = "/demo/ajax",
Handler = new AnonymousRouteHandler(AjaxResponder)
});
But now we have a problem. Our standard handler expects a redirect, not a data response:
public static string AjaxResponder(Session session, Dictionary<string, string> parms)
{
return "what???";
}
Yes, it's time for another refactoring. The handler needs finer control over the response, and thus should return a ResponsePacket, for example:
public static ResponsePacket RedirectMe(Session session, Dictionary<string, string> parms)
{
return Server.Redirect("/demo/clicked");
}
public static ResponsePacket AjaxResponder(Session session, Dictionary<string, string> parms)
{
string data = "You said " + parms["number"];
ResponsePacket ret = new ResponsePacket() { Data = Encoding.UTF8.GetBytes(data), ContentType = "text" };
return ret;
}
This change required touching a few places where the handler response used to be a string. The most relevant piece of code changed was in the router itself:
Route handler = routes.SingleOrDefault(r => verb == r.Verb.ToLower() && path == r.Path);
if (handler != null)
{
ResponsePacket handlerResponse = handler.Handler.Handle(session, kvParams);
if (handlerResponse == null)
{
ret = extInfo.Loader(session, fullPath, ext, extInfo);
}
else
{
ret = handlerResponse;
}
}
but the change took all of about 5 minutes, and here's the result:
You can of course return the data in JSON or XML -- that is completely independent of the web server, but you are advised to set the content type correctly:
- ContentType = "application/json"
- ContentType = "application/xml"
AJAX GET Verb
Also note that I used the "PUT" verb, which isn't necessarily appropriate, but I wanted to use it as an example. Look what happens if instead, we use the GET verb:
With the GET verb, the parameters are passed as part of the URL! Let's write a handler for this route:
Server.AddRoute(new Route()
{
Verb = Router.GET,
Path = "/demo/ajax",
Handler = new AnonymousRouteHandler(AjaxGetResponder)
});
Note that we have to handle the GET verb with both no parameters (the browser's request) and with parameters:
Interestingly, we can use the browser now to test the GET response -- note the URL:
What's that Underscore?
The underscore parameter is added by jQuery to get around Internet Explorer's caching, and is present only when cache is set to false and you're using the GET verb. Ignore it.
Step 8 - Internet vs. Intranet
Local vs. Public IP Addresses
Testing a web server locally on a 192.168... IP address is fine, but what happens when you deploy the site? I did this using an Amazon EC2 server and discovered (obivously) that there is a local IP behind the firewall, vs. the public IP. You can see the same thing with your router. We can get the public IP with this code which I found on Stack Overflow (sorry, I the link to give proper credit):
public static string GetExternalIP()
{
string externalIP;
externalIP = (new WebClient()).DownloadString("http://checkip.dyndns.org/");
externalIP = (new Regex(@"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}")).Matches(externalIP)[0].ToString();
return externalIP;
}
Possibly not the best approach, but it does work.
The salient thing here is that, when responding with a redirect, the public IP must be used, not the UserHostAddress:
if (String.IsNullOrEmpty(publicIP))
{
response.Redirect("http://" + request.UserHostAddress + resp.Redirect);
}
else
{
response.Redirect("http://" + publicIP + resp.Redirect);
}
Note that the above code for obtaining the external IP can be a bit slow, and should obviously only be done at server startup. Furthermore, it of course isn't necessary if you have an actual domain name. However, for testing your web application with a host provider without having registered a domain and pointing it to the host provider, the above step is absolutely necessary.
Domain Names
The above code is fine for testing when you don't have a registered domain name, but obviously we don't want the user to see the IP address whenever we do a redirect. I haven't testing this with an actual domain name, but the guidance here is, simply set publicIP with the actual domain name, for example:
Server.publicIP="www.yourdomain.com";
Step 9 - So You Want to Modify the HTML Dynamically (and why you ought to)
As I said in the introduction, with the capabilities of jQuery, AJAX, Javascript and professional third party components, I can only rarely imagine the need for any complex server-side HTML generation using embedded Ruby or C# along with the markup itself. That said, there is one reason you probably want the server to modify the HTML, and that is to deal with CSRF attacks.
Cross-Site Request Forgery (CSRF)
Here's a good explanation of CSRF and why you should care about it. However, do we need a runtime dynamic code compilation to spit out the necessary HTML? No, of course not. So, to deal with CSRF and more generally, server-side HTML manipulation, we'll add the ability for the web application to post-process the HTML before it is returned to the browser. We can do this in the router just before the HTML is encoded into a byte array:
string text = File.ReadAllText(fullPath);
text = Server.postProcess(session, text);
The default implementation provided by the server is:
public static string validationTokenScript = "<%AntiForgeryToken%>";
public static string validationTokenName = "__CSRFToken__";
private static string DefaultPostProcess(Session session, string html)
{
string ret = html.Replace(validationTokenScript,
"<input name='" +
validationTokenName +
"' type='hidden' value='" +
session.Objects[validationTokenName].ToString() +
" id='#__csrf__'" +
"/>");
return ret;
}
Refactoring time! A token is created when a new session is encountered:
public Session GetSession(IPEndPoint remoteEndPoint)
{
Session session;
if (!sessionMap.TryGetValue(remoteEndPoint.Address, out session))
{
session=new Session();
session.Objects[Server.validationTokenName] = Guid.NewGuid().ToString();
sessionMap[remoteEndPoint.Address] = session;
}
return session;
}
We can then, by default, implement a CSRF check on non-GET verbs (though we should probably be more selective than that, for the moment I'll just leave it at that):
public ResponsePacket Route(Session session, string verb, string path, Dictionary<string, string> kvParams)
{
string ext = path.RightOfRightmostOf('.');
ExtensionInfo extInfo;
ResponsePacket ret = null;
verb = verb.ToLower();
if (verb != GET)
{
if (!VerifyCSRF(session, kvParams))
{
return Server.Redirect(Server.onError(Server.ServerError.ValidationError));
}
}
...
}
private bool VerifyCSRF(Session session, Dictionary<string,string> kvParams)
{
bool ret = true;
string token;
if (kvParams.TryGetValue(Server.validationTokenName, out token))
{
ret = session.Objects[Server.validationTokenName].ToString() == token;
}
else
{
Console.WriteLine("Warning - CSRF token is missing. Consider adding it to the request.");
}
return ret;
}
So, given this HTML:
<!DOCTYPE html>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8" />
<title>Login</title>
<link type="text/css" rel="Stylesheet" href="/CSS/demo.css"/>
</head>
<body>
<form name="myform" action="/demo/redirect" method="post">
<%AntiForgeryToken%>
<div class="center-inner top-margin-50">
Username:
<input name="username"/>
</div>
<div class="center-inner top-margin-10">
Password:
<input type="password" name="password"/>
</div>
<div class="center-inner top-margin-10">
<input type="submit" value="Login"/>
</div>
</form>
</body>
</html>
We can inspect the source and see our token, for example:
<form name="myform" action="/demo/redirect" method="post">
<input name='__CSRFToken__' type='hidden' value='a9161119-de6f-4bb2-8e21-8d089d556c37'/>
And in the console window, on the post, we see:
If we omit the validation token, we get a warning in the console window:
Other HTML Replacement
When you have finer grained control over the server, you can pretty much do anything you want in terms of inventing your own set of token replacements. You could even feed the HTML to different parsers. For example, I really like the Slim language template supported in Ruby on Rails. For example, in the Slim syntax, the login HTML looks like this:
doctype html
html lang="en" xmlns="<a href="http:
head
meta charset="utf-8" /
title Login
link href="/CSS/demo.css" rel="Stylesheet" type="text/css" /
body
form action="/demo/redirect" method="post" name="myform"
| <%AntiForgeryToken%
.center-inner.top-margin-50
| Username:
input name="username" /
.center-inner.top-margin-10
| Password:
input name="password" type="password" /
.center-inner.top-margin-10
input type="submit" value="Login" /
This is not available with ASP.NET, Razor, etc., and replacing the Razor parser engine is not trivial. However, we can easily add a Slim to HTML post-process parser to our web server.
Issues for Another Day
CSRF and AJAX
Because of where we put this check in, we will get this warning on AJAX post/put/deletes as well, which is probably a good idea. Here's what our AJAX demo page looks like passing in the CSRF token:
<script type="text/javascript">
$(document).ready(function () {
$("#me").click(function () {
$.ajax({
url: this.href,
async: true,
cache: false,
type: "put",
data: {
number: 5,
__CSRFToken__: $("#__csrf__").val()
},
success: function(data, status)
{
alert(data);
}
});
});
});
</script>
This is probably not your typical implementation and it also results in some interesting browser behavior if the validation fails (sending a redirect as an AJAX response is a bit weird.) In any case, this becomes a rabbit hole that I don't want to pursue further and will leave it to the reader to decide whether AJAX requests should have a validation token. If you leave it off, then the console will simply issue a warning.
HTTPS
Websites should really use HTTPS nowadays, however I'm am going to leave this for another day, possibly a separate article or an addendum at some point to this article.
Decoding Parameter Values
It would probably be nice to decode parameter values, for example, replacing "+" with whitespace and "%xx" with the appropriate actual character.
Chaining Post Processing
Post processing the HTML is one of those things ripe for chaining, and is on the todo list.
What Else?
I'm sure there's other things that could be done!
Conclusion
What other major issues need to be taken care of? What horrendous mistakes did I make?
The idea is to keep the web server very small. I have a total of four classes (not including extension methods) and the whole thing is slightly less than 650 lines of code, comments and all.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







