Inspired by the great work of MarI/O, this is my own AI engine framework, not for some serious research, just for fun and to satisfy my personal hobby.
Introduction
The Google AlphaGO drew the attention of the entire world over the past few weeks, an artificial neural network shows its remarkable ability, with the deep learning technology, AlphaGO even beat one of the world's top go chess player.
Currently, the AI which makes us through him is a human who still exists only in the movies, as our world is too complex for the AI program to process. The world in a video game is a simplified version of our real world, we could not create a human like AI for the real world, but creating a player AI in the gaming world is possible.
As for me, my most joyful thing is playing a video game, and the Mario game is my most favorite as the NES game Mario brothers accompanied me in my childhood. A Mario game machine player MarI/O made by Seth Bling by using the evolutionary neuron network technology inspired me to step into the area of machine learning.
MarI/O video: https://www.youtube.com/watch?v=qv6UVOQ0F44
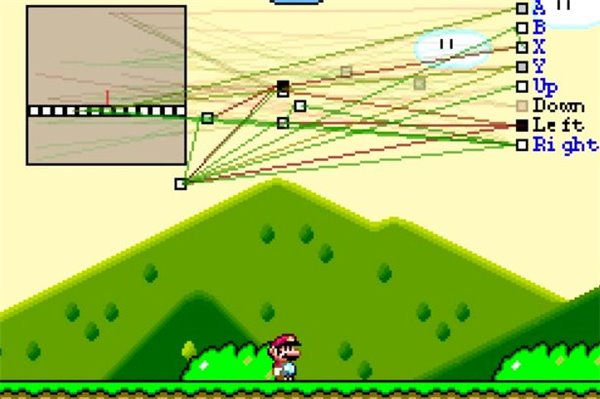
By using neuro-evolution to makes the machine learn to play Mario game
Inspired by the great work of MarI/O, I decided to develop my own AI engine framework, not for some serious research, just for fun and to satisfy my personal hobby.
Q-Learning Details
The Q-Learning is a kind of mode-free machine learning algorithm, and it is the most simple algorithm in the ML for machine-learning beginners like me. Generally, there are three steps in the Q-Learning in total:

How the QL_AI works: Overview of the three steps in Q-Learning
Phase 1: Input the Environment State
How Does the Snake See the World?
For generating the environment state as input, the snake must see the world at first. As the MarI/O just models the world by abstracting the game world as some blocks to simplify the state input, so that in this snake game, we just abstract the world as two points: the head of the snake and his food if not considering the deadly wall or some block obstacles. This two points just perfectly model the snake and the world outside. Considering we just want to training the snake to eat food, so that we just need to teach the snake how get close to food, there are two elements for generating the states for QTable can generate an identity state:
- The relative position description between the snake and food
- The snake its current movement direction
So that we can easily make the snake see the world by simply exporting the snake position and the food position for the QL_AI.
Dim pre = Distance(_snakeGame.Snake.Location, _snakeGame.food.Location)
Call _stat.SetState(_stat.GetNextState(Nothing))
-
Imports Microsoft.VisualBasic.DataMining.Framework.QLearning
Imports Microsoft.VisualBasic.GamePads.EngineParts
Imports Microsoft.VisualBasic.GamePads
Public Structure GameControl : Implements ICloneable
Dim position As Controls
Dim moveDIR As Controls
Public Overrides Function ToString() As String
Return $"{CInt(position)},{vbTab}{CInt(moveDIR)}"
End Function
Public Function Clone() As Object Implements ICloneable.Clone
Return New GameControl With {
.position = position,
.moveDIR = moveDIR
}
End Function
End Structure
Public Class QState : Inherits QState(Of GameControl)
Dim game As Snake.GameEngine
Sub New(game As Snake.GameEngine)
Me.game = game
End Sub
Public Overrides Function GetNextState(action As Integer) As GameControl
Dim pos As Controls = Position(game.Snake.Location, game.food.Location, False)
Dim stat = New GameControl With {
.moveDIR = game.Snake.Direction,
.position = pos
}
Return stat
End Function
End Class
Phase 2: Output Controls
The algorithm core of the Q-Learning is the QTable, QTable consists of basically two elements: the environment state and the actions’ q-values relative to a specific environment state. The index of the elements in the action state object in the code for the action, examples as 0 stands for action up, 1 for action down, etc. As the action output of the Q-Learning only has 4 direction controls: Up, Down, Left and Right, the QTable's action range is 4.
The Basic of QTable
Imports System
Imports System.Collections
Imports System.Collections.Generic
Imports Microsoft.VisualBasic.DataMining.Framework.QLearning.DataModel
Imports Microsoft.VisualBasic
Namespace QLearning
Public MustInherit Class QTable(Of T As ICloneable)
Implements IQTable
Public ReadOnly Property Table As Dictionary(Of Action) _
Implements IQTable.Table
Public ReadOnly Property ActionRange As Integer Implements IQTable.ActionRange
#Region "E-GREEDY Q-LEARNING SPECIFIC VARIABLES"
Public Property ExplorationChance As Single = 0.05F _
Implements IQTable.ExplorationChance
Public Property GammaValue As Single = 0.9F Implements IQTable.GammaValue
Public Property LearningRate As Single = 0.15F Implements IQTable.LearningRate
For example, on the code screenshot show above, Table variable in the QTable class, its key is a string that can represent some environment state, and the value of the dictionary is actions’ q-value. There are four values in each element in the dictionary in this snake game, its q-value element index stands for the four direction button on the joypad, and the q-value determines the program press which direction button is the best action.
At the QTable's initial state, there is no element in the QTable dictionary, but with the game continued playing, more and more environment states will be stored in the QTable, so that you can consider the QTable as one man's experience on doing something.
Exploration or Experience
In this QL_AI snake game controller program, we are using the e-greedy approach algorithm to make a choice of the program of how to deal with current environment state: Trying a new exploration or action based on the previous experience:
Public Overridable Function NextAction(map As T) As Integer
_prevState = CType(map.Clone(), T)
If __randomGenerator.NextDouble() < ExplorationChance Then
_prevAction = __explore()
Else
_prevAction = __getBestAction(map)
End If
Return _prevAction
End Function
Defines the Best Action
As the description above, the algorithm core of the Q-Learning is the q-value (rewards and penalty) for the actions on a specific environment state applied to the QTable object, so that we should define an action object to represent the best action under a specific environment state:
Imports Microsoft.VisualBasic.ComponentModel.Collection.Generic
Imports Microsoft.VisualBasic.Serialization
Namespace QLearning
Public Class Action : Implements sIdEnumerable
Public Property EnvirState As String Implements sIdEnumerable.Identifier
Public Property Qvalues As Single()
Public Overrides Function ToString() As String
Return $"[ {EnvirState} ] {vbTab}--> {Qvalues.GetJson}"
End Function
End Class
End Namespace
For the class code definition above, we know that in the current environment state EnvirState, the program that has some action choice, which the action is encoded as the index in the Qvalues array, and the array elements in the Qvalues property represents the action rewards on the current state EnvirState, the higher value of the element in the Qvalues means the higher reward of the action on current state so that we just let the program return the index of the max value in the Qvalues, and this index can be decoded as the best action. Gets the best action in the current state just like the function actions below:
Private Function __getBestAction(map As T) As Integer
Dim rewards() As Single = Me.__getActionsQValues(map)
Dim maxRewards As Single = Single.NegativeInfinity
Dim indexMaxRewards As Integer = 0
For i As Integer = 0 To rewards.Length - 1
If maxRewards < rewards(i) Then
maxRewards = rewards(i)
indexMaxRewards = i
End If
Next i
Return indexMaxRewards
End Function
In this snake game, there are only just four direction keys on the program's joypad, so that the Qvalues property in the Action class has four elements, stands for the q-value of each direction button that the machine program presses.
The four elements in the Qvalues represents the Q-value on each action.
After the best action, its index was returned from the Qtable based on the current environment state inputs, that we can decode the action index as the joypad controls of the snake:
Dim index As Integer = Q.NextAction(_stat.Current)
Dim action As Controls
Select Case index
Case 0
action = Controls.Up
Case 1
action = Controls.Down
Case 2
action = Controls.Left
Case 3
action = Controls.Right
Case Else
action = Controls.NotBind
End Select
Call _snakeGame.Invoke(action)
So that we can explain how the program takes action on the current environment states:
If the random is in the ranges of the ExplorationChance, the program will take a random action to try exploring his new world.
If not, then the program will make a decision of the best action based on the current environment state and the history in the QTable, that is, he takes action based on the experience.
Phase 3: Feedback (Learning or Adaptation)
As you can see in the __getBestAction function that is shown above, first, the program gets the q-value from current environment state, and then from the compares, the program he can choose an action index that would maximize the rewards in that direction.
Learning First Step: See the World
For generating the experience of doing something for the program, a dictionary add method was implemented for adding the new environment state to the QTable, so that this makes it possible for the program to learn the new world.
Protected MustOverride Function __getMapString(map As T) As String
Private Function __getActionsQValues(map As T) As Single()
Dim actions() As Single = GetValues(map)
If actions Is Nothing Then
Dim initialActions(ActionRange - 1) As Single
For i As Integer = 0 To ActionRange - 1
initialActions(i) = 0.0F
Next i
_Table += New Action With {
.EnvirState = __getMapString(map),
.Qvalues = initialActions
}
Return initialActions
End If
Return actions
End Function
Learning Step 2: Improvements on his Experience
For teaching a child, we often give some rewards when the kids are doing as we expect, so we did in the Q-Learning, we using the rewards to improving the program's experience on the action of the specific environment state:
Public Overridable Sub UpdateQvalue(reward As Integer, map As T)
Dim preVal() As Single = Me.__getActionsQValues(Me._prevState)
preVal(Me._prevAction) += Me.LearningRate * (reward + Me.GammaValue * _
Me.__getActionsQValues(map)(Me.__getBestAction(map)) - preVal(Me._prevAction))
End Sub
The Update Q value function can be expressed as the formula below:
Where Q is the q-values of the actions on the previous environment state, T is the best action of the previous environment state. R stands for the learning rate, E is the current environment state.
If the program's action makes him approach our goal, then we update the actions q-value with rewards, if not, then we update the actions q-value with penalty score so that after several time training loops, the program will work as we expected. The Q-Learning just acts like the dog's classical conditioning.
Classical conditioning: A statue of Ivan Pavlov and one of his dogs
Running the Example
For saving your time on running this example, you can download the trained snake QL_AI QTable data from this link:
And use the following command to start the snake with the trained data:
snakeAI /start /load "filepath-to-the-download-dataset"
Otherwise, you can also train the snake fresh. From the beginning to train the snake, just double click on the snake application, it will start running at a fresh state.
This article just tries to explain the basic concepts of the machine learning from a most simple snake game, and I hope you could get ideas to build a more powerful AI program that can deal with more complex environment situation.
Hope you could enjoy! ;-)


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






