|
I've built a system that allows a user to create an unlimited number of custom menus for any web page, or web application. I call this tool the "Main Menu Editor", and it's almost complete. Today, I completed a script that inserts arrow icons adjacent to each inline menu item.
If you click on the left or right arrow icon associated with an inline menu item, it reorders that inline menu item respectively. This is a simple solution that enables inline menu items to be reordered at any time.
I haven't coded the functionality as of yet, but that's the next step. It should be a quick and easy task to complete, and then I can move on.
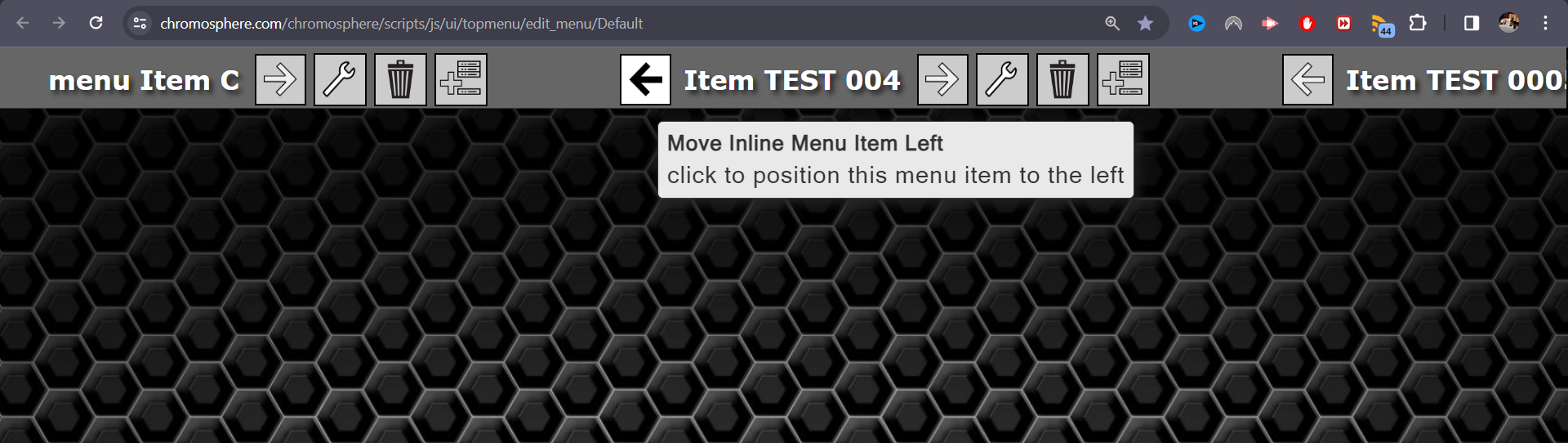
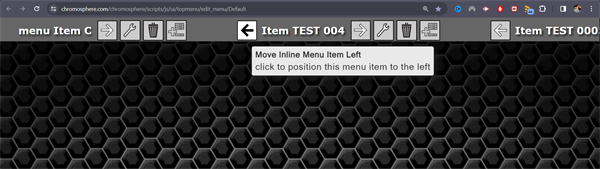
I've just added the mouseover "helper captions." These captions provide a short description of the icon's functionality, sort of like a tooltip that you often see in many interface designs.
I zoomed in and took a screenshot of the page as it is. The mouse cursor isn't visible, but it's hovering over an arrow icon and the tooltip is visible.
|
|
|
|
|
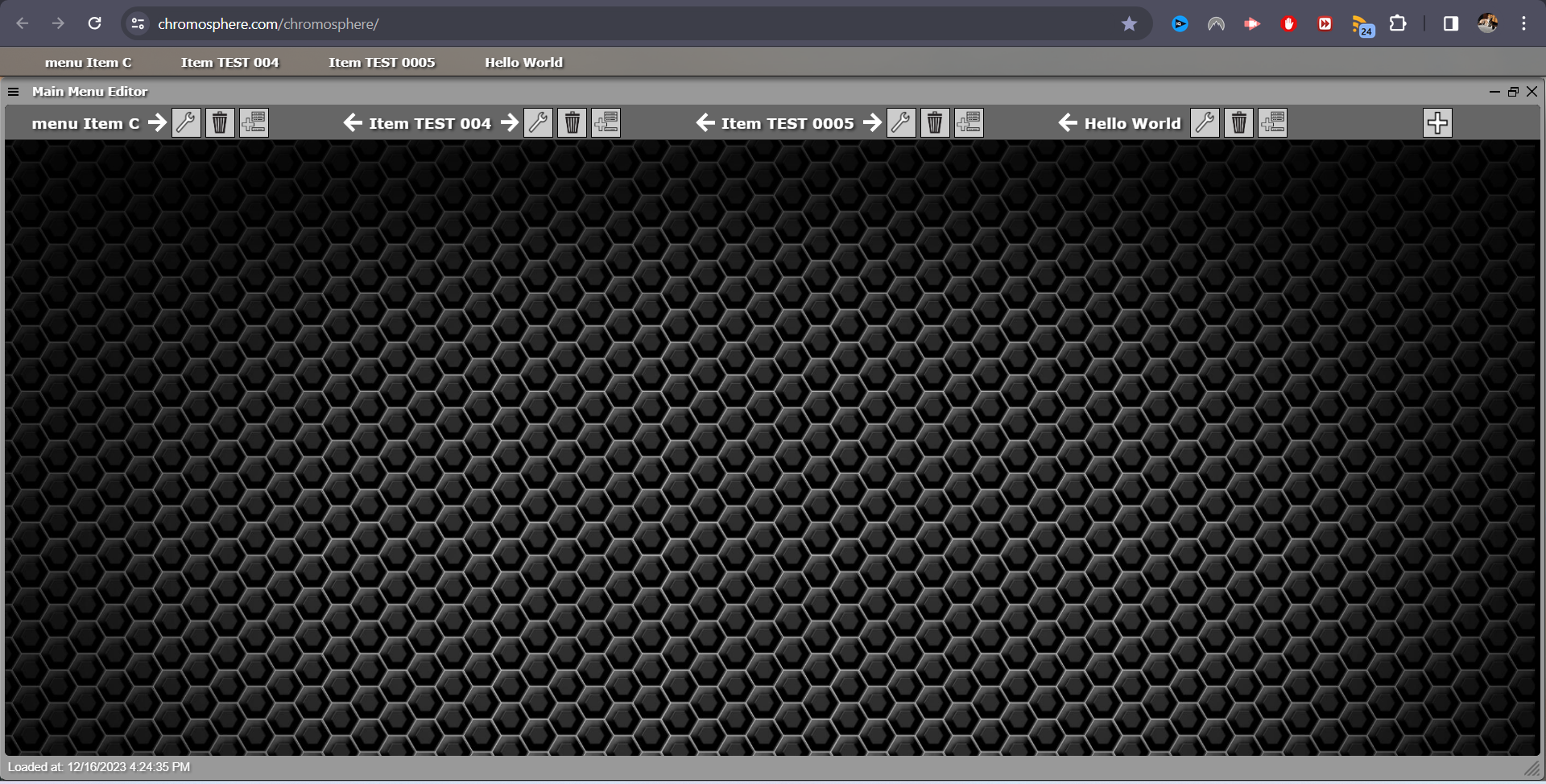
I decided to stop dragging my feet on this and just get it done. I have already added a feature that allows you to reorder stack menu items, but I haven't yet made a feature that allows you to change the order of the inline menu items located at the top of the main window. The original code does much the same thing, but it's too different to spend any time converting the existing code to work on the "Inline Menu Item Reorder" feature. So, I start from the beginning. This time, I'm adding the inline menu item "reorder arrows" that are simple. They're fast to implement, and still user-friendly.
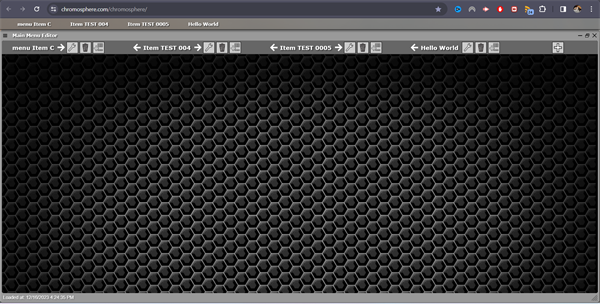
I made a short video of the Main Menu Editor showing the new white arrows added to the interface. They're not yet functional, but I expect the rest of the work for this feature to be quick and simple.
This is a link to the Main Menu Editor video:
Navigation Menu Editor - Adding Inline Menu Item Reorder feature - YouTube[^]
...and a screenshot:
...and a hyperlink:
Chromosphere.com - Navigation Menu Editor[^]
That's it for today.
|
|
|
|
|
It had been a few weeks since I had even touched Project Chromosphere.com. Several days ago, I checked the live site to see if everything was working correctly. It wasn't. I didn't spend any time looking into the bug until I dragged myself back to it, today.
What appeared to be happening was that data wasn't being pulled from the main database. I thought maybe I had forgotten to pay the database hosting bill. I updated my payment data and renewed the hosting for an additional year. That didn't change anything.
The error was being generated as an HTTP 500 server error. The error message mentioned something about the process pool possibly being full. I wasn't sure what it had to do with the application pool in IIS, but I recycled, stopped, and restarted the application pool. That didn't fix the error, either.
Since I hadn't touched anything for weeks, and the error popped up out of nowhere, I assumed it was an admin issue on one of my hosting servers. I downloaded and opened Microsoft SQL Server Manager, and copied the connection info directly from the server. I tried connecting to the database server. It worked fine. Everything was still there. I ran a SELECT query, and that worked fine.
Connecting to the database worked fine using MS SQL Server Manager, yet it was still not connecting via the website -- either run locally or run as published on the remote server. That narrowed it down a bit. I opened my Web.config file to check the database connection settings. I opened command prompt and ran a tracert command on the URL for the database which was provided from the server. I compared the IP addresses for connecting to the database with the one currently in use. It was a mismatch! My database hosting bastards had switched the database IP address without any notice or warning. Thanks, guys! ...I replaced the IP address to the database server in the Web.config file and, tah-dah! It worked! I'm glad I didn't have to resort to contacting technical support because that's always a pain in the ass.
I updated and re-built the site, published it, and it worked fine; no errors. I'm glad that's over and I can get back to work on the projects.
I made a full backup of the database, and new backups of the project itself. I'm now finishing up the backups and I think I'll call it a day. My dog Max hasn't been to the dog park in about a week, so it's way overdue as I usually take him every other morning.
This is a screenshot of today's desktop background. Nice!
|
|
|
|
|
In my web app, Project Chromosphere.com, I made a feature that automatically selects a new background wallpaper image for each day of the year. Here is a screenshot of today's background.
|
|
|
|
|
I just set up an experiment to test why I couldn't access the inner HTML of an iframe element the other night. I tried all sorts of ways to place HTML into an iframe, and then access its HTML content using JavaScript in the parent window. Nothing worked. I assumed that since iframe elements are considered to be window objects, placing HTML inside the iframe object tag would render the HTML as a regular browser window would. Right? Nope! It doesn't!
D'oh!
I read up on the subject tonight. I discovered that you can in fact grab data from an iframe element from a parent document. I had no idea that the "srcdoc" attribute ever existed. It turns out that placing HTML into an iframe requires you to set it to the value of the "srcdoc" attribute of the iframe element. You don't place HTML inside the iframe as innerHTML. That won't render the HTML. Placing HTML into the "srcdoc" attribute will render the HTML as it would in a separate browser window. That solves everything. I'm looking forward to tomorrow morning when I can implement my original idea. 
|
|
|
|
|
I haven't started working on my project yet today. I'm just thinking about the project as a whole. Where do I want to spend my energy right now?
I've built several custom HTTP clients as a professional software developer. All of the HTTP clients I have developed were built from the ground up. I didn't use any 3rd party components or other tools, except for one of the clients. I prefer to write my own custom code, but for certain features, such as sophisticated code editors, that isn't an option. I considered building my own code editor from the ground up, but I estimate it would take several years of full-time work to develop such an editor that is on par with the most robust code editors out there. Without the time and resources, I realize that I have to utilize a 3rd party component.
When it comes to building an HTTP client that runs on a server, I know I can build my own. While I could create a sophisticated HTTP client, it would take a great deal of time and resources. I could develop a simple HTTP client in no time, but I need something much more robust. So, I decided to look around for a 3rd party component. I need something to provide a base on which I can develop a sophisticated client. There are many out there. I could utilize the default HTTP client framework built into .NET, but it's nowhere near adequate for what I need.
After searching for a while, I found a 3rd party component that has everything I could want. It's called EO.WebBrowser, and developed by Essential Objects which is a company that creates .NET components. Its fundamental codebase is Chromium. Chromium is used as the codebase for popular web browsers, such as Google Chrome, and Microsoft Edge. I consider the Chromium codebase to be the best there is.
I studied the documentation for EO.WebBrowser. The component is incredibly versatile. You could build anything with it, essentially. You could create a custom desktop browser application, or implement it to be used on a server with .NET framework. So, after about an hour of studying the documentation, I decided to look into its license. I was shocked, but not surprised to see that a single-user license costs $799. Ouch! Do I think it's worth it? Yes. Do I have $799 dollars to spend on it? No. It can be used for free, but with conditions. That may not work for me. I'll have to look into it more.
The Essential Objects software company website is located at .NET PDF and WebBrowser Component[^]
|
|
|
|
|
I had an idea several months ago that I got around to testing just yesterday.
I spent about 12 hours experimenting to see if my idea could possibly be implemented.
My idea didn't sound possible, but I had to find out.
I wanted to make a web page that would fetch a specified URL,
remove the entire web page's DOM, and replace it with the HTTP
data of the given URL. I preferred to have it all done on the client side
using JavaScript, but I found that doing so doesn't work.
I was able to remove the entire DOM from the web page that loads the URL HTML,
and I was able to replace the blank page with the DOM of the HTML loaded from the
URL. It worked fine, but upon doing this, the new DOM didn't function. It was in place
and everything was present, but when adding the new DOM, the page didn't trigger the
body onload event. Without an onload event, the new page DOM wouldn't operate.
To make the new DOM load, I created a synthetic load event. After removing the original
page DOM, and replacing it with the new DOM, I triggered the load event. That worked fine,
and it called the 'start()' function. It generated an error stating that 'start()' is
undefined. So, I made a function to reload all the JavaScripts on the page by refreshing
their src attribute. Still, it didn't work.
I realized that I couldn't do this using JavaScript alone. I would have to build
a server-side HTTP client component to do the job, but something else occurred to me.
I could take the HTML data that I fetched, submit that data to the server, and let the server
write the new page HTML and send it to the client.
I couldn't believe it. I didn't think it was possible, and if it were possible, I didn't
think I could pull it off. Then I got it to work for the first time and I laughed! I
couldn't believe that it worked perfectly. I felt I had done the impossible.
Try it out here: Chromosphere: HTTP GET HTML[^]
You can check out the JavaScript I wrote to handle the client-side of this feature: https://chromosphere.com/chromosphere/scripts/js/ui/sandbox/http_get_html/functions/get_html_d.js[^]
Notice that my hyperlink to the page has query string parameters. The first parameter is named 'url' and its value is the URL
string you want to load. The 'id' parameter designates an HTML element that you want to grab inside the URL's document HTML. I haven't yet implemented that feature just yet, but it pulls up pages from any given URL within my domain. There's the issue of Cross-Origin Resource Sharing that prevents a javascript HTTP client from loading data from URLs located on different websites.
|
|
|
|
|
|
This blog will serve the purpose of
logging my progress on project Chromosphere.com,
a personal side-project that I started in 2016.
Currently, I'm using Twitter/X to log my progress,
but it's too limited.
@ChromoSphereCom
The project's current progress is published at:
https://chromosphere.com

|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin