Here I’ll go through the required theory to understand what’s behind the actual model of a DIY solution.
Deep fakes - the use of deep learning to swap one person's face into another in video - are one of the most interesting and frightening ways that AI is being used today.
While deep fakes can be used for legitimate purposes, they can also be used in disinformation. With the ability to easily swap someone's face into any video, can we really trust what our eyes are telling us? A real-looking video of a politician or actor doing or saying something shocking might not be real at all.
In this article series, we're going to show how deep fakes work, and show how to implement them from scratch. We'll then take a look at DeepFaceLab, which is the all-in-one Tensorflow-powered tool often used for creating convincing deep fakes.
In the previous article we went through some of the different approaches you can take to generate deep fakes. In this article, I’ll go through the required theory to understand what’s behind the actual model of a DIY solution.
To create our deep fakes, we’ll use Convolutional Networks, which have proven to be very successful in this area. These networks, combined with an autoencoder architecture result in what we’ll be working with. Here’s a brief overview of what these are about and how to use them in deep fake generation.
Convolutional Autoencoders Applied to Deep Fakes
We’ve been discussing autoencoders since the first article of this series and now it’s time to understand how you can use them to generate deep fakes.
To generate deep fakes, we must gather two face sets — src and dst — that are large enough to cover all possible facial expressions of two individuals, assign an autoencoder to each one of them, and train them until they reach an acceptable error metric (each autoencoder should copy as seamlessly as possible the input face to the output). Finally, we swap autoencoders’ decoders and start the face transformation process. I know this can be a little confusing at first, so let’s visualize the process:
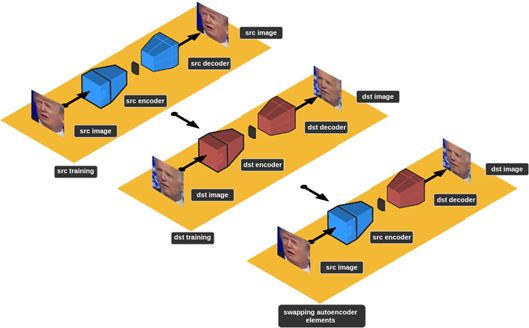
Autoencoders aren’t the only elements of the entire deep fake generation process, but they’re certainly the most important. Their training will require several iterations, sometimes over 50000, and without a powerful GPU, it could take days. That’s why we’ll sometimes need to support our training process in the Cloud.
Now that we have a basic understanding of the whole generation process, we’re good to deep dive into actual code! In the next article, I’ll go through what’s required to preprocess videos and prepare them to be fed into our models. See you there!
Sergio Virahonda grew up in Venezuela where obtained a bachelor's degree in Telecommunications Engineering. He moved abroad 4 years ago and since then has been focused on building meaningful data science career. He's currently living in Argentina writing code as a freelance developer.





