Starting today, we initiate a series that explores neural networks and deep learning. The objective is to uncover the complexities of utilizing neural networks to accomplish tasks that elude other algorithms.
Introduction
Neural networks are a computational model inspired by the way biological neural networks in the human brain function that consist of interconnected nodes, or artificial neurons, organized in layers. Information is processed through these layers, with each connection having an associated weight that is adjusted during the learning process. Neural networks are commonly used in machine learning to recognize patterns, make predictions, and perform various tasks based on data inputs.
We will delve into the details of this definition in subsequent posts, demonstrating how neural networks can outperform other methods. Specifically, we will begin with logistic regression and illustrate, through a straightforward example, how it may fall short and how deep learning, on the contrary, can be advantageous. As usual, we adopt a step-by-step approach to progressively address the challenges associated with this data structure.
We consulted the following books as references to compose this series.
This series was originally posted here.
What is Logistic Regression?
We will not delve into the details of logistic regression in this post, as we have already dedicated an entire series to this topic earlier. We refer the reader to this link. Here, we will simply recap the final results.
Logistic regression is a statistical method used for binary classification problems, where the outcome variable has two possible classes. It models the probability that an instance belongs to a particular class, and its predictions are in the form of probabilities between 0 and 1. The logistic function σσ (sigmoid) is employed to transform a linear combination of input features into a probability score.
Important
The sigmoid function that appears in logistic regression is not arbitrary and can be derived through a simple mathematical study. Once again, refer to our previous post for detailed explanations.
Observing Logistic Regression in Action
To witness logistic regression in action, we will swiftly implement it with ML.NET in the straightforward example outlined below, where we have two possible outcomes for 2-dimensional inputs.
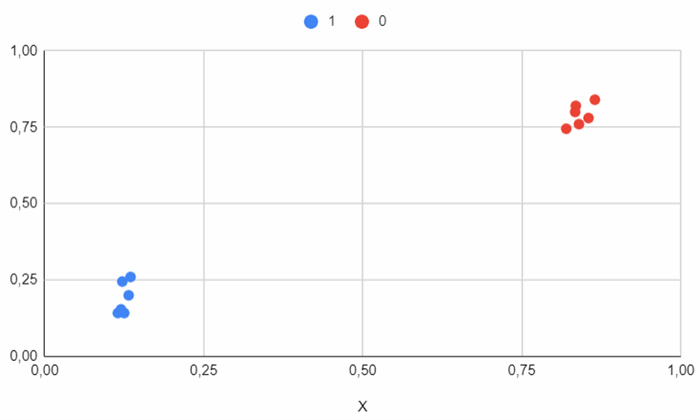
The corresponding dataset is illustrated below:
X;Y;Category
0.12;0.154;1
0.135;0.26;1
0.125;0.142;1
0.122;0.245;1
0.115;0.142;1
0.132;0.2;1
0.84;0.76;0
0.834;0.8;0
0.855;0.78;0
0.865;0.84;0
0.835;0.82;0
0.82;0.745;0
...
Implementing Logistic Regression with ML.NET
ML.NET is an open-source machine learning framework developed by Microsoft that allows developers to integrate machine learning models into their .NET applications. ML.NET supports a variety of machine learning tasks, including classification, regression, clustering, and recommendation.
The C# code for employing logistic regression is presented below:
static void Main(string[] args)
{
var ctx = new MLContext();
var path = AppContext.BaseDirectory + "/dataset.csv";
var data = ctx.Data.LoadFromTextFile<DataRecord>
(path, hasHeader: true, separatorChar: ';');
var dataPipe = ctx.Transforms.Concatenate("Features", new[]
{
"X", "Y"
}).Append(ctx.BinaryClassification.Trainers.LbfgsLogisticRegression
(featureColumnName: "Features"));
var model = dataPipe.Fit(data);
var record = new DataRecord()
{
X = 0.25f,
Y = 0.24f
};
var pe = ctx.Model.CreatePredictionEngine<DataRecord, DataRecordPrediction>(model);
var category = pe.Predict(record);
}
Here are the predicted values for some generated inputs.
| X | Y | prediction |
| 0.25 | 0.24 | 1 |
| 0.05 | 0.02 | 1 |
| 0.92 | 0.86 | 0 |
| 0.5 | 0.55 | 0 |
This example is a simplified one, as the data is well-separated, making it relatively easy for a method like logistic regression to predict the correct values. But how will this algorithm perform with a significantly more complex dataset?
What Happens if Data Is Not Linearly Separable?
We will now apply logistic regression to the dataset depicted below. It is notably more intricate than the previous one (despite being in a two-dimensional space, facilitating data representation), and, most importantly, the data is not linearly separable. The objective is to observe how logistic regression behaves under such circumstances.

We will utilize the identical C# code as above (with different data), and observe some predicted values.
| X | Y | prediction |
| -0.25 | 0.24 | 0 |
| 0.45 | -0.72 | 0 |
| 0.92 | 0.86 | 0 |
| -0.5 | -0.55 | 0 |
Here, it is evident that many predicted values are inaccurate. The algorithm consistently returns the same predicted probability (0.5), indicating that it cannot adapt to the specific problem at hand.
This is normal as we must recall that logistic regression applies a sigmoid to linear data and can only be effective in separating linearly separable data. As it is clearly not the case in the given sample, this method proves to be inappropriate.
Is It Possible to Alleviate This Phenomenon?
The short answer is yes: theoretically, there are mathematical methods that can address this issue, and we will observe them in action in the next post. The extended answer is that, in practice, it can be very challenging.
So, How to Overcome This Issue?
The idea is not revolutionary and simply involves initially applying a fixed nonlinear transformation ff to the inputs instead of directly working with the original inputs.
The logistic regression algorithm is then applied to the new dataset.
Information 1
The approach of mapping the input space into another space to make the data linearly separable or more tractable in this new space is the foundation for kernel methods (from which we can derive support vector machines and similar techniques). This process can be highly fruitful if correctly applied and has robust advantages.
Information 2
In the figure above, the two spaces have the same dimensions for representation convenience, but in practice, there is no reason for them to be the same.
How Should We Proceed in Our Case?
This process might sound a bit theoretical and abstract initially, but we will see how to put it into practice in the example from the previous post. For that, we will apply the following function to the inputs.
f(X,Y)=XY
Here are the results of this mapping for some values:
| XX | YY | f(X,Y)f(X,Y) |
| -0.9 | 0.5664324069 | -0.509789165 |
| 0.89 | -0.4208036774 | -0.374515273 |
| 0.18 | 0.9626599405 | 0.173267893 |
| ... | ... | ... |
Information
In our example, the final space is a 1-dimensional space, whereas the input space was 2-dimensional. This is by no means a general rule of thumb: the final space can be much larger than the input space.
Data is linearly separable in the new space.
Applying the Logistic Regression Algorithm to the New Dataset
Once the mapping has been performed on the input space, it suffices to apply logistic regression to the new dataset, and we can hope to make accurate predictions. Obviously, the predicted values must be first mapped to the new space before being evaluated by the trained model.
| XX | YY | f(X,Y)f(X,Y) | prediction |
| -0.25 | 0.24 | -0.06 | 1 |
| 0.05 | -0.02 | -0.001 | 1 |
| 0.92 | 0.86 | 0.7912 | 0 |
| -0.5 | -0.55 | 0.275 | 0 |
And now the predictions are perfectly accurate.
What are the Drawbacks of This Approach?
The mathematical method we developed above appears to be well-suited for data with irregular shapes: it essentially involves magically performing a mapping between spaces to make the data linearly separable in the final space.
However, the challenge lies in how to identify this mapping. In our toy example, it was relatively easy to deduce the transformation because we could visualize the data graphically. But real-world scenarios involve many more dimensions and much more complex data that may be challenging or impossible to visualize. This is indeed the major issue with this process: we can never be certain that in the final space, our data is distinctly linearly separable.
Does this mean that the current approach is not productive? Absolutely not! While we can uphold the conceptual idea of mapping data to another space, the key lies in refining the process of executing this mapping. Imagine the prospect of automatically discovering this mapping instead of relying on guesswork, wouldn't that be a significant advancement? This automation exists: enter neural networks and deep learning.
What are Neural Networks?
We will discuss the rationale behind neural networks for multiclass classification (with KK classes), but the following can be readily adapted to regression.
The goal is to extend this model by making the basis functions ϕ1, ..., ϕD depend on parameters and then to allow these parameters to be adjusted along with the coefficients w1, ..., wD during training.
The idea of neural networks is to use basis functions that are themselves nonlinear functions of a linear combination of the inputs. That leads to the basic neural network model which can be described as a series of functional transformations.
How Does It Work in Concrete Terms?
We continue to assume that we have a dataset composed of N records, each of which possesses D features. To illustrate, our previous toy example had 2 features (X and Y).
- Construct M linear combinations a1, ..., aM of the input variables x1, ..., xD
Information
What is M, and what does it stand for? That is not very important for the moment, but the intuitive idea behind this formula is to construct a mapping from our original D-dimensional input space to another M-dimensional feature space. We will revisit this point later in this post.
σ can be the sigmoid (or other activation function) in the case of binary classification or the identity in the case of regression.
Information 1
We can observe that the final expression of the output is much more complex than that of simple logistic regression. This complexity provides flexibility, as now we will be able to model complex configurations (such as non-linearly separable data), but it comes at the expense of learning complexity. We now have many more weights to adjust, and the algorithms dedicated to this task are not trivial. It is this complexity that hindered neural network development in the late 80s.
Information 2
The neural network can be further generalized by customizing the activation functions; for example, we can use tanh instead of the sigmoid.
It is quite customary to represent a neural network with a graphical form, as shown below.
This graphical notation has several advantages over the mathematical formalism, as it can emphasize two key points.
- First, we can consider additional layers of processing.
Information
The more layers, the more flexible the neural network becomes. In this context, one might think that increasing the number of layers will eventually enable the model to handle all real-world situations (which is the premise of deep learning). However, this approach significantly increases the complexity of learning parameters and, consequently, demands substantial computing resources.
- Second, we can see that M represents the number of "hidden" units. The term "hidden" stems from the fact that these units are not part of the input or output layers but exist in intermediate layers, where they contribute to the network's ability to learn complex patterns and representations from the data.
Information
M must be chosen judiciously: if it's too small, the neural network may struggle to generalize accurately. On the other hand, if it's too large, there is a risk of overfitting, accompanied by an increase in the learning of parameters.
The number of input and output units in a neural network is generally determined by the dimensionality of the dataset, whereas the number MM of hidden units is a free parameter that can be adjusted to give the best predictive performance.
Bishop (Pattern Recognition and Machine Learning)
Now that we have introduced the formalism and demonstrated how complex configurations can be represented by neural networks, it's time to explore how the parameters and weights involved in the process can be learned. We will delve into the dedicated procedure developed for this purpose.
To avoid overloading this article, readers interested in this implementation and in the backpropagation algorithm can find the continuation here.
History
- 17th January, 2024: Initial version
Nicolas is a software engineer who has worked across various types of companies and eventually found success in creating his startup. He is passionate about delving into the intricacies of software development, thoroughly enjoying solving challenging problems.





