We are launching a series of articles on decision trees, taking a progressive approach with a particular focus on the C4.5 algorithm. Our goal is to blend theoretical concepts with practical implementation (in C#), offering clear illustrations of the associated challenges.
Introduction
Decision trees are a popular machine learning algorithm used for both classification and regression tasks. They are versatile, can be applied to a wide range of problems, are easy to understand and interpret, making them a valuable tool for both beginners and experts in machine learning. They work well for both numerical and categorical data and can handle non-linear relationships between features and the target variable. The C4.5 algorithm is one of the well-known algorithms for constructing decision trees and our aim in this series is to implement it.
The following textbooks on this topic merit consultation. These books extend beyond decision trees and cover a myriad of expansive and general machine learning topics.
This post was originally published here.
Truly Understanding Entropy
Decision trees employ the C4.5 algorithm, which, in turn, utilizes the concept of entropy. In this section, we will attempt to clarify this crucial notion introduced by Shannon in the late 1940s.
Important
We should not be intimidated by the term "entropy". Although it may evoke memories of thermodynamics and seem daunting, we will discover that it is entirely comprehensible when presented effectively.
You should call it entropy (...). As nobody knows what entropy is, whenever you use the term, you will always be at an advantage! (Von Neumann to Shannon)
Entropy originates from information theory, and it is essential to address this aspect initially.
Strictly speaking, information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Specifically, it seeks to quantify the information content within a message and explore methods for compressing it to facilitate efficient transmission to another location.
This definition is somewhat informal and may appear abstract, but in reality, we unconsciously apply its principles in our daily lives.
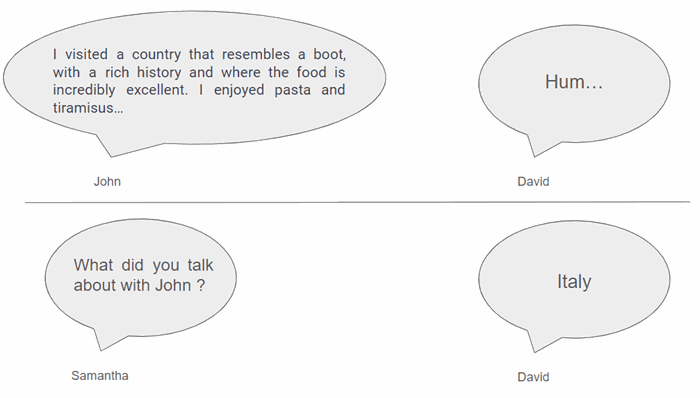
Here, David is condensing information by informing Samantha that John visited Italy during his holidays. Once Samantha learns that John discussed Italy, she can infer that he might have highlighted various famous monuments or shared other well-known facts about the country. In any case, she wouldn't be astonished if David mentioned that John talked about the Colosseum or mentioned visiting Rome or Milan.

But if David suddenly mentioned something unexpected, Samantha might be surprised because this information was not evident within the given context.
Entropy simply involves expressing this situation in mathematical terms, nothing more and nothing less. Entropy attempts to quantify the level of surprise or uncertainty in a message.
Entropy(He visited Roma)=0
Entropy(He met his girlfriend)>0
And How to Do That? Enter the Surprise Concept
Therefore, entropy seeks to mathematically express the idea that certain events are predictable and do not provide significant information, while others are highly rare (or even impossible) and, conversely, offer valuable information. Reconsider the previous sentence: we use terms like events, certainty, and impossibility. This terminology is linked to probability, and it is fitting to utilize probability theory to articulate our concepts.
Informally, the lower probability we assigned to an event, the more surprising it is, so surprise seems to be some kind of decreasing function of probability.
P(He visited Italy and met Italian people)=1 ⟹ surprise(He visited Italy and met Italian people)=0
P(He visited Italy and met Dante)=0 ⟹ surprise(He visited Italy and met Dante)=+∞
As a probability can only exist within the range of 0 and 1, our objective is to identify a function, denoted as I, which maps from [0,1] to [0,+∞], with the conditions that I(0)=+∞ and I(1)=0.
The following examples satisfy that property and can be considered as candidates for our definition of surprise.
I(P)=1/P−1
I(P)=−log2(P)
I(P)=−lnP
Which Function to Ultimately Choose?
In fact, we are not at the end of the story. Since we can choose among several functions, it would be advantageous to select one that not only quantifies surprise but also verifies some desirable properties. Wouldn't it be wonderful if we could kill two birds with one stone?
Consider event A: "John met his girlfriend at the Tower of Pisa" and event B: "John found money on the ground". These two events are clearly independent (John could meet his girlfriend without finding money or find money without meeting his girlfriend), and we can observe that Samantha's surprise progressively increases when she hears about both of these events: her surprise is ADDITIVE.
Mathematically, we would like to have I(P(A,B)=I(P(A)P(B))=I(P(A))+I(P(B)). This equation is a Cauchy functional equation, and we know that the solution is the logarithm.
More precisely, there must exist a∈R such that I(P)=alnP. If a=−1, then I(P)=−lnP, if a=−ln2, then I(P)=−log2P and so forth.
Shannon chose a=−ln2.
Thus, I(P)=−log2P
And Where Did Entropy Go?
Consider the two following scenarios:
- A fair coin is tossed once. What is the expected outcome ? If it lands heads, we would not be very surprised but have gained an information we did not have. If it lands tails, we would not be very surprised either but once again have gained an information we did not have. In any case, regardless of the outcome, we have gained information.
- A biased coin (which lands heads 9 out of 10 times) is tossed once. What is the expected outcome? If it lands heads, we would not be surprised at all, and, in fact, we can say that not much information has been gained. Conversely, if it lands tails, we would be quite surprised and have gained information.
Entropy attempts to quantify these facts: how much information can we, on average, obtain after the toss? In this sense, entropy is quite similar to an expectation in probability.
Entropy is usually denoted as H. In the first case, H(P)=(1/2)(−log2(1/2))+(1/2)(−log2(1/2))=1. In the second case, H(P)=(1/10)(−log2(1/10))+(9/10)(−log2(9/10))=0.469.
This result aligns with intuition: in the first case, we consistently gain information every time, whereas in the second case, we gain information infrequently. It seems normal that the entropy in the first case is higher than in the second case.
In simple terms, entropy quantifies the amount of information contained in a random variable. It reaches its maximum when all outcomes are equally likely, and it decreases as the probability distribution becomes more certain or focused.
In the context of decision trees and the C4.5 algorithm, entropy will often be used to measure the impurity or disorder in a set of data points, helping guide the process of choosing splits to build an effective decision tree.
What Does It Quantify Concretely?
Imagine a scenario where an individual is tasked with selecting a number between 1 and 100, and our goal is to guess this number by asking binary questions. How should we approach this? As developers, we understand that the most effective method is to employ a dichotomy, as depicted in the figure below:
Drawing on our knowledge from computer science, we recognize that the number of steps required to arrive at the chosen number is precisely log2100. If we calculate the entropy H for this scenario, we have H=log2100. Therefore, entropy measures the minimum number of steps (units of entropy in the jargon) needed in a binary scheme to acquire all the information contained in a message.
We now delve into the intricacies of the ID3 algorithm, applying the knowledge we've acquired to gain a profound understanding of its workings.
Decision trees possess a simplicity that renders them accessible to both novices and seasoned machine learning practitioners. Operating akin to a rules-based engine, their decision-making process is easily explicable, making them a pivotal data structure in the realm of machine learning.
The current challenge lies in automating the construction of these decision trees, and our journey begins by delving into the ID3 algorithm.
Important
The goal is indeed to construct the tree, but the real challenge lies in obtaining the smallest possible tree to ensure quick usage when classifying an unknown input.
What is the ID3 Algorithm ?
We must be aware that several trees can be built based on the features we successively consider. For instance, with the example above, we could start with the Humidity feature instead of the Weather feature.
As there are various ways to construct the tree, we thus need to rely on heuristics to build it. And the heuristic is as follows: the algorithm constructs the tree in a greedy manner, starting at the root and selecting the most informative feature at each step.
This last sentence contains two important intuitions.
- Construct in a greedy manner: It appears intuitive and natural to split based on the feature that provides the most information.
- Select the most informative feature: The concept of the most informative feature might seem informal initially, but fortunately, we learned in the previous article how to define this concept mathematically. Therefore, we will choose the feature with the highest entropy, indicating the highest quantity of information.
The continuation of this article requires a few mathematical formulas that are not easily written on this site. Visit this link if you wish to comprehend the IC3 algorithm in action and learn how to implement the C4.5 algorithm. Alternatively, you can download the enclosed source code to initiate the utilization of decision trees.
History
- 19th December, 2023: Initial version
Nicolas is a software engineer who has worked across various types of companies and eventually found success in creating his startup. He is passionate about delving into the intricacies of software development, thoroughly enjoying solving challenging problems.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 , bookmarked for reading soon ...
, bookmarked for reading soon ...