Here we'll suggest a DNN model for detecting a moose on images. Then we'll provide Python code to generate input data for training a DNN with Caffe. Then we explain how to launch Caffe. Finally, we demonstrate the training log and explain the results.
Introduction
Unruly wildlife can be a pain for businesses and homeowners alike. Animals like deer, moose, and even cats can cause damage to gardens, crops, and property.
In this article series, we’ll demonstrate how to detect pests (such as a moose) in real time (or near-real time) on a Raspberry Pi and then take action to get rid of the pest. Since we don’t want to cause any harm, we’ll focus on scaring the pest away by playing a loud noise.
You are welcome to download the source code of the project. We are assuming that you are familiar with Python and have a basic understanding of how neural networks work.
In the previous article, we assembled a dataset for moose detection, which contains images with objects of the moose class and the background class. In this article, we’ll develop a classifier DNN model and train it on our dataset. We’ll use Caffe to create and train the DNN. Please install this framework on your PC to follow along.
Developing a DNN
DNN development begins with creating a model structure. Since we’re going to use our neural network on a Raspberry P, the model should be lightweight so it can run at an adequate speed.
Designing an optimized DNN model from scratch is a rather complex task, which we’re not going to describe in detail here. We suggest using the following network architecture:

This is a Caffe DNN model visualized with a free online editor. It might not be the absolute best model, but it’s definitely good enough for our purposes.
This is derived from the AlexNet architecture, which was the first (and the simplest) network successfully applied to image classification. We’ve trimmed and optimized the original architecture for classifying a low number of object categories. The resulting model has four convolutional layers with 64-128-128-64 kernels (convolutional filters).
There are also two pooling layers for reducing dimensions of the input picture to 128 x 128 pixels. The intermediate fully connected (FC) layer has 256 neurons, and the last FC layer has two neurons (one per object category to classify: Background and moose).
One more component we need is the training model, which is a modified classification model that replaces the input and output layers.
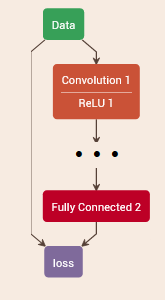
The input layer of the training model must specify the sources of labeled data for training and testing. The output layer must specify the loss function to minimize output during training.
To provide sources of labeled data, we create text files containing paths to all our sample images with labels (identifiers for object category of an image). Let’s organize our sample images into the following folders:
PI_PEST
As you can see, we have two main folders, Learning and Testing, for training and testing, respectively. The 0 subfolders are for the background samples and the 1 subfolders are for the moose samples.
Start by moving 500 sample images for every class to the Testing directories, and all the remaining images to the Learning directories. Now let’s write some Python code to generate source files:
import os
import numpy as np
import cv2
class TrainFiler:
def get_labels(self, folder):
subfolders = os.scandir(folder)
labels = []
for classfolder in subfolders:
class_name = os.path.basename(classfolder)
files = FileUtils.get_files(classfolder)
for (i, fname) in enumerate(files):
label = fname + " " + class_name
labels.append(label)
return labels
def save_labels(self, labels, filename):
with open(filename, 'w') as f:
for label in labels:
f.write('%s\n' % label)
def gen_train_files(self, learn_folder, test_folder, learn_file, test_file):
labels = self.get_labels(learn_folder)
self.save_labels(labels, learn_file)
labels = self.get_labels(test_folder)
self.save_labels(labels, test_file)
We can run it like so:
learn_folder = r"C:\PI_PEST\Learning"
test_folder = r"C:\PI_PEST\Testing"
learn_file = r"C:\PI_PEST\classeslearn.txt"
test_file = r"C:\PI_PEST\classestest.txt"
filer = TrainFiler()
filer.gen_train_files(learn_folder, test_folder, learn_file, test_file)
This results in two source files with the following data:
…
C:\PI_PEST\Learning\0\vlcsnap-2020-10-26-16h13m39s332(x253,y219,w342,h342)fliprotate15.png 0
C:\PI_PEST\Learning\0\vlcsnap-2020-10-26-16h13m39s332(x253,y219,w342,h342)fliprotate_15.png 0
C:\PI_PEST\Learning\1\vlcsnap-2020-10-21-13h46m55s365(x106,y28,w633,h633).png 1
C:\PI_PEST\Learning\1\vlcsnap-2020-10-21-13h46m55s365(x106,y28,w633,h633)flip.png 1
…
…
C:\PI_PEST\Testing\0\vlcsnap-2020-10-26-16h16m22s719(x39,y36,w300,h300)smooth5rotate15.png 0
C:\PI_PEST\Testing\0\vlcsnap-2020-10-26-16h16m22s719(x39,y36,w300,h300)smooth5rotate_15.png 0
C:\PI_PEST\Testing\1\vlcsnap-2020-10-26-16h08m31s421(x276,y0,w566,h566)flipsharpen5.png 1
C:\PI_PEST\Testing\1\vlcsnap-2020-10-26-16h08m31s421(x276,y0,w566,h566)flipsharpen5rotate15.png 1
…
The last thing to do before we start the training process is to prepare the so-called solver specification. For the Caffe framework, this is a text file that contains the training process parameters.
net: "classes_learn_test.prototxt"
test_iter: 1000
max_iter: 100000
base_lr: 0.001
solver_mode: CPU
The net parameter specifies the path to the ‘training’ model, test_iter is the period of accuracy testing, max_iter is the maximum number of iterations to run, base_lr is the start value of the learning rate, and the solver_mode parameter defines whether the training process executes on CPU or GPU.
To launch Caffe for model training, we need to copy the following data files to the Caffe executable folder: classes_learn_test.prototxt (the training file), classeslearn.txt and classestest.txt (the generated training and testing data files), and classes_solver.prototxt (the solver specification file).
Launch the training process with the following command:
caffe.exe train -solver=classes_solver.prototxt
In the console window that opens, you can see the progress of the training process:
I1028 09:10:24.546773 32860 solver.cpp:330] Iteration 3000, Testing net (#0)
I1028 09:13:12.228042 32860 solver.cpp:397] Test net output #0: accuracy = 0.95
I1028 09:13:12.229039 32860 solver.cpp:397] Test net output #1: loss = 0.209061 (* 1 = 0.209061 loss)
I1028 09:13:12.605070 32860 solver.cpp:218] Iteration 3000 (1.83848 iter/s, 543.929s/1000 iters), loss = 0.0429298
I1028 09:13:12.605070 32860 solver.cpp:237] Train net output #0: loss = 0.00469132 (* 1 = 0.00469132 loss)
I1028 09:13:12.608062 32860 sgd_solver.cpp:105] Iteration 3000, lr = 0.000800107
I1028 09:19:11.598755 32860 solver.cpp:447] Snapshotting to binary proto file classes_iter_4000.caffemodel
I1028 09:19:11.641045 32860 sgd_solver.cpp:273] Snapshotting solver state to binary proto file classes_iter_4000.solverstate
I1028 09:19:11.661990 32860 solver.cpp:330] Iteration 4000, Testing net (#0)
I1028 09:21:51.567586 32860 solver.cpp:397] Test net output #0: accuracy = 0.971
I1028 09:21:51.568584 32860 solver.cpp:397] Test net output #1: loss = 0.0755974 (* 1 = 0.0755974 loss)
I1028 09:21:51.942620 32860 solver.cpp:218] Iteration 4000 (1.92553 iter/s, 519.337s/1000 iters), loss = 0.0283988
I1028 09:21:51.942620 32860 solver.cpp:237] Train net output #0: loss = 0.0119124 (* 1 = 0.0119124 loss)
I1028 09:21:51.942620 32860 sgd_solver.cpp:105] Iteration 4000, lr = 0.000751262
I1028 09:29:05.931291 32860 solver.cpp:447] Snapshotting to binary proto file classes_iter_5000.caffemodel
I1028 09:29:06.011082 32860 sgd_solver.cpp:273] Snapshotting solver state to binary proto file classes_iter_5000.solverstate
I1028 09:29:06.042008 32860 solver.cpp:330] Iteration 5000, Testing net (#0)
I1028 09:32:13.374222 32860 solver.cpp:397] Test net output #0: accuracy = 0.877
I1028 09:32:13.374222 32860 solver.cpp:397] Test net output #1: loss = 0.861016 (* 1 = 0.861016 loss)
I1028 09:32:13.743319 32860 solver.cpp:218] Iteration 5000 (1.60823 iter/s, 621.8s/1000 iters), loss = 0.000519958
I1028 09:32:13.743319 32860 solver.cpp:237] Train net output #0: loss = 0.000306881 (* 1 = 0.000306881 loss)
I1028 09:32:13.745313 32860 sgd_solver.cpp:105] Iteration 5000, lr = 0.000708472
The value we should monitor is accuracy. It increases to 97.1% on iteration 4000, and then begins to decrease. This can be due to overfitting of the trained model. So we should stop the process and get the model file from the 4000th iteration.
Next Steps
In the next article, we’ll show you how to develop a simple motion detector and combine it with the trained DNN model to detect moose on video.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





