Here we look at some of the code behind training our model, and validating the model.
In this series, we’ll learn how to use Python, OpenCV (an open source computer vision library), and ImageAI (a deep learning library for vision) to train AI to detect whether workers are wearing hardhats. In the process, we’ll create an end-to-end solution you can use in real life—this isn’t just an academic exercise!
This is an important use case because many companies must ensure workers have the proper safety equipment. But what we’ll learn is useful beyond just detecting hardhats. By the end of the series, you’ll be able to use AI to detect nearly any kind of object in an image or video stream.
You’re currently on article 5 of 6:
- Installing OpenCV and ImageAI for Object Detection
- Finding Training Data for OpenCV and ImageAI Object Detection
- Using Pre-trained Models to Detect Objects With OpenCV and ImageAI
- Preparing Images for Object Detection With OpenCV and ImageAI
- Training a Custom Model With OpenCV and ImageAI
- Detecting Custom Model Objects with OpenCV and ImageAI
In the previous article, we cleaned our data and separated it into training and validation datasets.
Now we can begin the process of creating a custom object detection model. The general steps for training a custom detection model are:
- Train the model
- Validate the model; if validation is poor, tweak and retrain
- Visually test the model and the results
- Deploy the model
Training Our Model
Let's jump right into training our model. Create a new code block and enter the following:
from imageai.Detection.Custom import DetectionModelTrainer
trainer = DetectionModelTrainer()
trainer.setModelTypeAsYOLOv3()
trainer.setDataDirectory(data_directory="hardhat")
trainer.setTrainConfig(object_names_array=["person hardhat"], batch_size=4, num_experiments=20,
train_from_pretrained_model="yolo.h5")
trainer.trainModel()
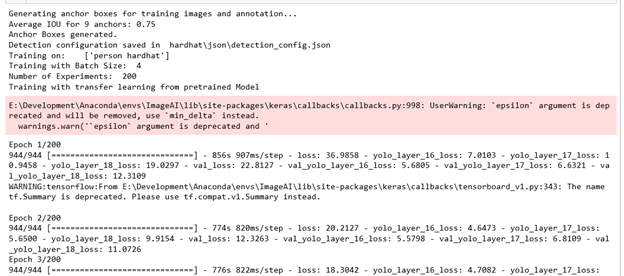
This code block utilizes a new method in ImageAI's detection class, DetectionModelTrainer. The process for training any model is:
- Define a new
DetectionModelTrainer() method. - Set the model type as YOLOv3. At this point in time, YOLOv3 is the only model type that can be trained using ImageAI.
- Set the directory that contains your data. Note that this folder must contain one folder named "train" and one named "validation." These folders must each contain one folder called "images" and another called "annotations."
- Set the trainer’s configuration as follows:
- Specify the names of the annotations used within the images. In our case, we use only "person hardhat."
- Define the batch size, four in our case. This determines how many images the model will train in each batch. The higher your batch size, the better your model can be trained but, remember, the more powerful GPU you need.
- Specify how many iterations of modelling to perform with
num_experiments. The more iterations, the better your end result, but the longer it will take. - Specify, if desired, a pretrained model to transfer learning from, to give a better result quicker.
- Start the model training process with
trainModel().
The model will begin training and output a status for each cycle (or epoch). For each of these cycles, a loss is reported that determines if a model is better than in the previous cycle. If it is, that model will be saved, so make sure you have plenty of disk space free!
Validating the Model
Training a model can take a very long time. This model, with 20 iterations, took a bit over four hours to train. Some recommendations for training models suggest more than 200 hours. Before we leave our computer for several days to train a model, let's see what’s created after our model has been trained over 20 iterations.

In your "hardhat" directory, you’ll see that some extra directories have been created: "cache," "json," "logs," and "models." The two important directories here are "json" and "models." The "json" directory contains the JSON configuration file required to use the model. The "model" directory contains a number of rather large model files with incremental numbers. Each of these files is the result of an iteration of model training that was better than the last.
So we have a number of models that are theoretically better and better, depending on the cycle number. Let’s test these out by validating them. Start a new code block and enter the following:
trainer.evaluateModel(model_path="hardhat\models\detection_model-ex-020--loss-0008.462.h5",
json_path="hardhat\json\detection_config.json", iou_threshold=0.5,
object_threshold=0.3, nms_threshold=0.5)
The only change you’ll need to make is the model path with the string: hardhat\models\detection_model-ex-020--loss-0008.462.h5, as each training run will be different. This method takes the following parameters:
model_path – specifies the model you wish to run a validation againstjson_path – specifies the configuration file for the model trainingiou_threshold – represents the ratio of intersection and union of the predicted and actual bounding boxobject_threshold – the confidence level of detections to removenms_threshold – the confidence level when multiple bounding boxes are detected.
When we run this validation for a 20-iteration model, we get an average precision of 0.84464, or roughly 84%, which isn’t bad. But how does that compare against some of the others? Let's expand our code block to the following:
model05 = trainer.evaluateModel(model_path="hardhat\models\detection_model-ex-005--loss-0014.238.h5",
json_path="hardhat\json\detection_config.json", iou_threshold=0.5,
object_threshold=0.3, nms_threshold=0.5)
model10 = trainer.evaluateModel(model_path="hardhat\models\detection_model-ex-010--loss-0011.053.h5",
json_path="hardhat\json\detection_config.json", iou_threshold=0.5,
object_threshold=0.3, nms_threshold=0.5)
model15 = trainer.evaluateModel(model_path="hardhat\models\detection_model-ex-015--loss-0009.620.h5",
json_path="hardhat\json\detection_config.json", iou_threshold=0.5,
object_threshold=0.3, nms_threshold=0.5)
model20 = trainer.evaluateModel(model_path="hardhat\models\detection_model-ex-020--loss-0008.462.h5",
json_path="hardhat\json\detection_config.json", iou_threshold=0.5,
object_threshold=0.3, nms_threshold=0.5)
print('---------------------------------------------------------')
print('Iteration 05:', model05[0]['average_precision']['person hardhat'])
print('Iteration 10:', model10[0]['average_precision']['person hardhat'])
print('Iteration 15:', model15[0]['average_precision']['person hardhat'])
print('Iteration 20:', model20[0]['average_precision']['person hardhat'])
print('---------------------------------------------------------')
This code block will take some time to run as it needs to load 4 different models, validate them, and save the results, so if you do run this, walk away and come back in a little while. When this code block eventually finishes, the last few lines will give you the results:
- 5 Iterations – 71%
- 10 Iterations – 78%
- 15 Iterations – 83%
- 20 Iterations – 84%
So, from these results, the more we iterate, the better our model gets. However, at some point, there are diminishing returns, so you need to take that into account when training your model as well.
Up Next
In this article, we learned how to train a custom image detection model using a prepared dataset.
Next, we’ll look at how to use this model to detect if people are wearing hardhats.
Hi! I'm a Solution Architect, planning and designing systems based in Denver, Colorado. I also occasionally develop web applications and games, as well as write. My blog has articles, tutorials and general thoughts based on more than twenty years of misadventures in IT.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






