Introduction
This post aims to describe the application of Long Short-Term Memory (LSTM) Neural Networks (NNs) for spam detection. The library used to build the NN model was the Deeplearning4j, a deep learning library for Java (as the name suggests), but actually the code for this post was written in Scala.
In order to apply neural networks for language processing tasks. a suitable word representation is needed, one that allows the words to be used as inputs for the NN. The word representation to be used here will be the Global Vectors, or GloVe, representation.
The data set used contains three sections: a set of 1000 spam messages for training, a set 1000 of ham messages also for training and a set of 100 mixed (spam and ham) messages for testing. All the messages are labeled accordingly.
Hence, the specific objectives of this post are to show how to use Deeplearning4j to generate a data set consisting of labeled sequences of (GloVe) word vectors and then used this data set to train and test a LSTM NN. Additionally, explanations and justifications for the parameters and configurations used will be given.
Architecture and Workflow
Deeplearning4j (DL4j from now on) has in its backend the numerical computation library Nd4j. Making a Python reference, ND4j can be considered the NumPy of Java's universe. ND4j, just like NumPy, uses n-dimensional arrays, or NDArrays. Then DL4j provides a couple of facilities for loading and translating real-world data sets into NDArrays. The image below shows these facilities and the workflow for the problem in hand.
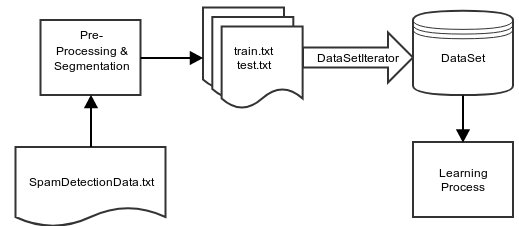
An initial file is given: "SpamDetectionData.txt". As was mentioned before, this file contains all the training and test data. It is then segemented into two main files: "train.txt" and "test.txt". Then enters DL4j. The DataSetIterator interface is implemented and it is to create iterator objects to run through the data set.
This iterator is moved thorugh the data set using class to the overriden next() (or next(n)) method(s), which returns a DataSet object, that actually contains the next data sample or batch.
Although the image above shows the DataSet object being fed directly into the learning process, the API allows one to feed the iterator instead; but internally the DataSet will be fetched through the iterator anyway.
Using the Code
Global Vectors Word Representation
As mentioned before the GloVe word vector representation will be used. The algorithm to generate these word representations is explained in this 2014 paper by Jeffrey Pennington, Richard Socher and Christopher D. Manning, and the intention is to encode words as vectors but preserving their semantic relationship.
The algorithm is relatively simple. Consider a large set of documents, like all Wikipedia entries. In one pass, the algorithm collects all the words in this set in a big matrix X where each line and each column represents each word, and each cell X(i, j) stores the number of times the words i and j co-occurred in the set; this is the word-word co-occurrence matrix.
With this matrix you one can compute the probability of a word j occur in the context of word i as P(j|i)=X(i, j)/sum(X(i,:)). But what that authors argue is that, given three words i, j and k, the probabilities ration P(k|i)/P(k|j) will be large for a word k semantically related to i, small for a word k semantically related to j and close to 1 if k is not semantically related to neither. Then one should find a function F that could encode this relationship between i, j and k into vectors wi, wj and wk, i. e, find F such that F(wi, wj, wk)=P(k|i)/P(k|j). After some mathematical work (please check the paper), they come up with the following cost function J=sum(sum(f(X(i, j))*(dot(xi, xj) - bi - bj - log(X(i, j))), i), j), where the wheighting function f must obey certain conditions expressed in the paper. So, minimizing J with respect to wi, wj and the biases bi and bj gives the GloVe word representation.
In this post a pre-trained set was used. It consists of 50-dimensional word vectors trained with Wikipedia 2014 and Gigaword 5 corpora. This set was loaded into a hash map gloveMap[String, INDArray] whose keys are the words and values are the their vector representation in a NDArray object.
val gloveMap = new mutable.HashMap[String, INDArray]()
val gloveIt = Source.fromFile(gloveFile).getLines()
for (line <- gloveIt) {
val word = line.takeWhile(_.isLetter)
val rest = line.substring(line.indexOf(" ")).trim.replaceAll(" ", ",")
val glove = Nd4j.readTxtString(IOUtils.toInputStream(
"[NDArray]" +
"{\n" +
"\"filefrom\":\"dl4j\",\n" +
"\"ordering\":\"c\",\n" +
"\"shape\":[1, " + gloveDim + "],\n" +
"\"data\":\n" +
"[" + rest + "]\n" +
"}", StandardCharsets.UTF_8))
gloveMap += (word -> glove)
}
Data Preparation
Before implementing the data set iterator, the raw data from the file "SpamDetectionData.txt" must be put in a suitable format to be used. To achieve this, the following pre-processing actions will be performed:
- Replacing the labels "Spam" and "Ham" by 0 and 1 respectively;
- Strinping out all the HTML tags; and
- Isolating punctuation, as the GloVe data set has vector representations for them, so they must be treated as words.
As a result, two files are generated: "train.txt", with all the training set, and "test.txt", with the test set. But in the original file, "Spam"-labelled and "Ham"-labelled are disposed in two continuous sequences. But in order to ease the data fetching for training, the tranining set file should contain alternating samples. In this way it is possible to feed the training data directly, without the need of shuffling of any sort. So, two temporary files area created, one for "Spam" and other for "Ham" training samples, and a final "train.txt" file is generated by the merging of the previous two with alternating "Spam" and "Ham" samples. The process is illustrated in the figure below. The test file, in turn, can be generated diretly.
The procedure is implemented in the method generateSeparateFiles() of the class Main.

The Data Set Iterator Class
The custom iterator for the spam detection data set inherits from the interface DataSetIterator and implements its virtual methods. In this post focus will be given to the constructor and the method next(num: Int): DataSet.
The constructor receives five arguments (which are also properties):
path: the path too the directory where the "train.txt" and "test.txt" files are in;batchSize: the size of the data set batch;maxNumWords: as the length of the messages can vary, this integer sets an limit, and a message longer than this is truncated;gloveHash: the hash mapping word to its NDArray vetor representation; andisTraining: true if the iterates throgh the training set and false if iterates the test set.
class SpamDataIterator(val path: String,
val batchSize: Int,
val maxWordNumber: Int,
val gloveHash: mutable.HashMap[String, INDArray],
val isTraining: Boolean) extends DataSetIterator {
}
The word vector sequences representing messages are all stored in memory in one pass in the constructor. This is only possible because the data set is small, but a different strategy should be applied for larger data sets. The INDArrays that will compose the entire training set are allocated in advance:
val inputs: INDArray = Nd4j.create(nLines, gloveHash.head._2.shape()(1), maxWordNumber)
val targets: INDArray = Nd4j.create(nLines, 2, maxWordNumber)
inputs store all word vector sequences, targets store the desired output for each word vector sequences ([1, 0] for spam and [0, 1] for ham), nLines represents the number of samples and gloveHash.head._2.shape()(1) gives the dimension of the GloVe vectors (50 for this case). So input and target are three-dimensional arrays. The table below describes the dimensions of the training NDArrays:
| | Inputs Array | Targets Array |
| Dimension 1 | # of samples | # of samples |
| Dimension 2 | Input size | # of possible output lables |
| Dimension 3 | Maximum message length | Maximum message length |
As stated before, if the message contains more words than maxWordNumber, it is truncated; but if it has fewer words than this limit some mechanism is need to inform the learning procedure where the data ends and the padding begins. For this masks are used, and they are needed for both the inputs and the targets arrays.
val inputsMask: INDArray = Nd4j.zeros(nLines, maxWordNumber)
val targetsMask: INDArray = Nd4j.zeros(nLines, maxWordNumber)
For every i and j where inputs(i, :, j) has a valid word vectors (no padding), inputsMask(i, j) should be one. In targetsMask's case, it should be all zeros, except at the position of the last valid word vector, where it is 1.
In the following snippet, line represents the a line in the file being iterated ("train.txt" or "test.txt") and lineCount its index. For the formation of the inputs:
val inputVal = line.substring(2).split(" ")
var idx = 0
inputVal.foreach({ w =>
if (gloveHash.contains(w) && idx < maxWordNumber) {
inputs.put(
Array(
NDArrayIndex.point(lineCount),
NDArrayIndex.all(),
NDArrayIndex.point(idx)
),
gloveHash(w)
)
idx += 1
}
})
In this code, for each word w in a line of the train/test file, its GloVe representation (given by gloveHash(w)) is put in the corresponding position of the inputs array. The NDArrayIndex class is used to select regions of NDArrays. In the above code it would mean inputs(lineCount, :, idx) = gloveHash(w), with lineCount being the index of the sample (word vector sequence) and idx being the index of the word vector within the sequence.
The overriden next(num: Int): DataSet method is given below. It returns a slice of the data set previouly loaded, as a DataSet object.
override def next(num: Int): DataSet = {
val dsSliceIdx = Array(
NDArrayIndex.interval(position, Math.min(position + num, lineCount)),
NDArrayIndex.all(),
NDArrayIndex.all()
)
val dataSet = new DataSet(
inputs.get(dsSliceIdx(0), dsSliceIdx(1), dsSliceIdx(2)),
targets.get(dsSliceIdx(0), dsSliceIdx(1), dsSliceIdx(2)),
inputsMask.get(dsSliceIdx(0), dsSliceIdx(1)),
targetsMask.get(dsSliceIdx(0), dsSliceIdx(1))
)
position += num
dataSet
}
Model Building
The topology of the NN used is illustrade in the image. It has 50 inputs, two hidden LSTM layers with 30 and 15 neurons (respectively) with hyperbolic tangent (tanh) activation functions, and an output layer with two softmax neurons.
For the creation of a NN with this topology in DL4j, the builder pattern is employed, as shown in the code below. It can also be seen that the pattern is also applied in the creation of the layers. The learning rate and network topology were chosen by trial-and-error, until some acceptable performance were reached.
val mlpConf = new NeuralNetConfiguration.Builder()
.seed(Random.nextInt())
.learningRate(1e-2)
.weightInit(WeightInit.XAVIER)
.updater(Updater.ADAGRAD)
.list()
.layer(0, new GravesLSTM.Builder()
.nIn(gloveDim)
.nOut(30)
.activation(Activation.TANH)
.build())
.layer(1, new GravesLSTM.Builder()
.nIn(30)
.nOut(15)
.activation(Activation.TANH)
.build())
.layer(2, new RnnOutputLayer.Builder()
.nIn(15)
.nOut(2)
.activation(Activation.SOFTMAX)
.lossFunction(LossFunctions.LossFunction.MCXENT)
.build())
.build()
The weight initialisation algorithm employed was the Xavier algorithm (WeightInit.XAVIER). According to this post by Andrew Jones, it consists of drawing the weights from a probability distribution with zero mean and variance var(W) = 1 / nInputs, usually uniform or Gaussian. Checking the paper by Xavier Glorot and Yoshua Bengio that Andrew references as the paper that proposes the initialization heuristic, it can be seen that the authors initialized the weights in each layer from a uniform distribution in the interval [-sqrt(6) / sqrt(nj + nj+1), sqrt(6) / sqrt(nj + nj+1))], where nj is the number of neurons in the j-th layer.
For updating the gradients, the adaptive gradient algorithm Adagrad (Updater.ADAGRAD) was used. It has the property of emphasizing features that only occurs rarely. Quoting from the original paper by John Duchi, Elad Hazan and Yoram Singer:
Informally, our procedures give frequently occurring features very low learning rates and infrequent features high learning rates, where the intuition is that each time an infrequent feature is seen, the learner should “take notice.” Thus, the adaptation facilitates finding and identifying very predictive but comparatively rare features.
A more practical view of Adagrad is given by Sebastian Ruder in this survey.
Back to DL4j, now the NN object must be create using the above configuration object.
val mlp: MultiLayerNetwork = new MultiLayerNetwork(mlpConf)
mlp.init()
Model Training and Evaluation
The model is trained by calling the fit method of the mlp NN object. This method receives the iterator of the training set, trainIt. Since each call to fit implies a pass through the entire set with the iterator, at the end of each epoch we should reset the iterator.
for (i <- 0 until nEpochs) {
mlp.fit(trainIt)
spamIt.reset()
val evaluation = mlp.evaluate(testIt)
println(evaluation.stats())
}
At the end of each epoch the model is evaluated using an evaluation object. This object is returned by the method evaluate of the NN object, which receives the test set iterator as an argument. The evaluation object has a method stats the returns a string with a brief performance report. The output for the model presented here is given below for 1 epoch (i. e., one single pass through the training set), showing the the network classified all test samples right.
Examples labeled as Spam classified by model as Spam: 43 times
Examples labeled as Ham classified by model as Ham: 57 times
==========================Scores========================================
Accuracy: 1
Precision: 1
Recall: 1
F1 Score: 1
========================================================================
The model score per iteration curve was obtained through the DL4j UI and is shown below.
Final Remarks
This post showed how to use DL4j for training a LSTM NN for spam detection, with GloVe word vectors representations. Although the system showed good results, some variables may be explored in order to obtain better results:
- Higher dimensional GloVe vectors: in larger data sets it may be useful to have higher dimensional vectors, since it would mean a higher capacity to encode word meaning, and there are pre-trained GloVe sets available with higher vector dimensions;
- Update algorithm: Adagrad was chosen because of its property of emphasizing rare features, but other algorithms improved some asspects of it and others have been proposed, so this could also be a point for improvement; and
- Network topology and parameters: this is a point that always can be changed in the quest of better results, mostly by trial-and-error, but keeping the model simple enough is important.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





