Here we'll learn how you can select and download annotated images from Google Open Images Dataset.
Introduction
Deep neural networks are awesome at tasks like image classification. Results that would have taken millions of dollars and an entire research team a decade ago are now easily available to anyone with a half-decent GPU. However, deep neural networks have a downside. They can be very heavy and slow, so they don’t always run well on mobile devices. Fortunately, Core ML offers a solution: it enables you to create slim models that run well on iOS devices.
In this article series, we’ll show you how to use Core ML in two ways. First, you’ll learn how to convert a pre-trained image classifier model to a Core ML and use it in an iOS app. Then, you’ll train your own Machine Learning (ML) model and use it to make a Not Hotdog app – just like the one you might have seen in HBO’s Silicon Valley.
Up until now, we’ve dealt with a trained ML model - converted it from ResNet to Core ML, then used it in a sample iOS application. To detect hot dogs in images, we’ll build our own model.
What Do You Need to Build a Hot Dog Detection Model?
To build an image classification model capable to differentiate a hot dog from "not a hot dog," you need three things:
- Photographs containing a hot dog
- Photographs without a hot dog
- A mechanism for training a model on these photographs
The most time-consuming task in a typical ML project is collecting and preparing data. Training a neural network from the ground up requires vast amounts of data – at least hundreds, but most likely thousands records, with millions or even billions not unheard of. The ResNet model, which we’ve used in the previous article, was trained on 1.28 Million images from the ImageNet 2012 classification dataset. All these images had to be acquired, collected, and manually annotated with one of 1,000 labels.
This data "hunger" would cause a lot of pain if not for two things:
- Transfer learning from pre-trained models
- Publicly available datasets
Transfer Learning to the Rescue
Training of a neural network is not a one-time event. The model learns by analyzing batch after batch of data, each time updating its parameters to reduce the prediction error. Here is a common scenario in image classification:
- Model is first trained on millions of the various images, to assign each one to one of the hundreds of classes.
- During the training, the various model parameters, such as filters in the convolutional neural networks (CNNs), learn specific tasks. Some tasks are pretty basic, such as detection of edges or colors. Other filters build on this "basic" knowledge to learn the detection tricks for more complex patterns, such as human figures, eyes, or hands. These layers are known as "feature extraction layers."
- Feature extraction layers are followed by classification layers, which are responsible for assigning a label to a picture. The classification part of the network is usually much simpler than the feature extraction part.
- The model is trained again, this time on a different set of images (or even for a different task). Because the model is already capable of detecting basic features, which should not change much regardless of what appears in the picture, only the classification layer(s) has to be updated.
The process where we use a ready model (usually trained on a massive dataset) and train it further on our own data, is called "transfer learning."
What makes transfer learning so attractive is that it requires much fewer data – and, therefore, much less time – for data preparation and training.
For many image classification tasks, you can get decent results using only about 30 images per class, with training taking minutes, not hours. We don’t mean "production quality" – but good enough for a demo or a proof of concept.
We are going to use transfer learning in the next article, when training our model.
Open Datasets
Collecting 30 images per class doesn’t seem like heavy lifting… but still, taking pictures of 30 different hot dogs may be too time-consuming.
Luckily, there are datasets with images we can use for free. One of such datasets, Google Open Images Dataset, contains about 9 Million of annotated images including approximately 20,000 image-level classes. Great news for us: one of these classes is "Hot dog":
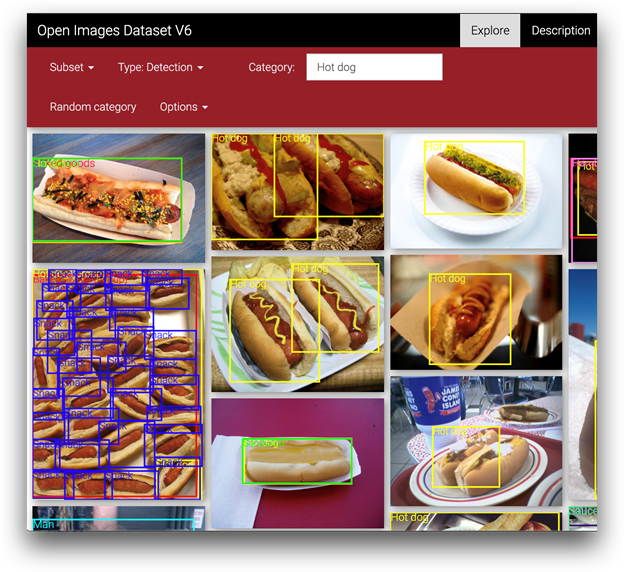
The annotations and images are licensed under CC_BY 4.0 and CC_BY 2.0, respectively).
If you have a lot of HDD space to spare, you may download the entire dataset; however, for our purposes, we’ll only need a small selection of images.
Explore the Google Open Images Dataset
As we need a relatively small set of images for our training, let’s use Python code to get only what we need — see the notebook included in the code download.
We’ll need three files from the download page to proceed:
- File containing the defined labels (
LABEL_DESCRIPTIONS) - File containing a list of image URLs (
IMAGE_URLS) - File matching images with a labels (
IMAGE_LABELS)
The available dataset is split into training, validation, and test sets. To illustrate the process, and avoid downloading too much data, we’ll use only the test dataset. If you need more images to train your model, consider using the remaining datasets.
The files we’ll use in the following steps are:
IMAGE_URLS = 'https://storage.googleapis.com/openimages/2018_04/test/test-images-with-rotation.csv'
IMAGE_LABELS = 'https://storage.googleapis.com/openimages/v5/test-annotations-human-imagelabels.csv'
LABEL_DESCRIPTIONS = 'https://storage.googleapis.com/openimages/v6/oidv6-class-descriptions.csv'
Now we are ready to start downloading data (using a few libraries, including pandas):
import numpy as np
import pandas as pd
import os
import random as rnd
image_urls = pd.read_csv(IMAGE_URLS)
image_labels = pd.read_csv(IMAGE_LABELS)
label_descriptions = pd.read_csv(LABEL_DESCRIPTIONS)
image_labels = image_labels[image_labels.Confidence == 1]
print("image_urls count:", len(image_urls))
print("image_labels count total:{}, unique images: {}".format(len(image_labels), len(image_labels.ImageID.unique())))
print("label_names count:", len(label_names))
Expected output:
image_urls count: 125436
image_labels count total:1110124, unique images: 124480
label_names count: 19994
Let’s take a peek at the data structure in the downloaded files:

You can see relationships where ImageID is the key used to join image_urls with image_labels, and LabelName is the key to join image_labels with label_descriptions.
A single image can have multiple labels assigned to it .
We’ll use these relationships in a moment. First, however, let’s try to find our hot dogs here:
hotdog_related_classes = label_descriptions[label_descriptions['DisplayName'].str.startswith('Hot dog')]
print(hotdog_related_classes)
We have three classes related to hot dogs. To focus on the most representative examples we’ll:
- Teach the model to recognize hot dogs using images labeled "Hot dog"
- Teach the model to recognize things other than hot dogs, using a random selection of images with labels not related to "Hot dog" in any way
This leads to the following selection code:
hotdog_class = label_descriptions[label_descriptions['DisplayName'] == 'Hot dog']
hotdog_label_name = hotdog_class[‘LabelName'].to_list()[0]
hotdog_labels = image_labels[(image_labels.LabelName == hotdog_label_name)]
hotdog_related_label_names = hotdog_related_classes[‘LabelName'].to_list()
other_labels = image_labels[~image_labels.LabelName.isin(hotdog_related_label_names)]
print("hot dog label count:", len(hotdog_labels.ImageID.unique()))
print("other label count:", len(other_labels.ImageID.unique()))
The code produces the following results:
hot dog label count: 47
other label count: 124480
As you can see, we don’t have too many hot dog images in our dataset – just 47 - but this should be enough for our purposes. On the other hand, we have a lot of images without hot dogs - over 120,000.
Select and Download Images
We’ll start with a helper function that will help us select a random subset of URLs for "not a hot dog" images:
def get_image_url_by_labels(labels, max_row_count: int = 0) -> []:
sel_images = image_urls[image_urls.ImageID.isin(labels.ImageID.to_list())]
if max_row_count == 0:
return sel_images.OriginalURL.to_list()
else:
return sel_images.sample(min(len(sel_images), max_row_count)).OriginalURL.to_list()
Equipped with this function, we can select images for download (setting a fixed random seed to ensure repeatable results):
rnd.seed(101)
hotdog_image_urls = get_image_url_by_labels(hotdog_labels)
other_image_urls = get_image_url_by_labels(other_labels, max_row_count = 120)
print("hot dog url count:", len(hotdog_image_urls))
print("other url count: ", len(other_image_urls))
Generated output:
hot dog url count: 47
other url count: 120
As you can see, we’ve decided to add 47 hot dog images and 120 random images containing objects other than hot dogs. It is hard to decide upfront if such a split is correct. On the one hand, it should reflect how often you see a hot dog (vs "not a hot dog") in real life. On the other hand, if we use too many "not a hot dog" pictures for training, the model would tend to detect everything as "not a hot dog." Why? Because this would harm its accuracy less than incorrect hot dog detection. Proper balancing of a dataset would require a separate article (or a series of them), so for now let’s assume that our guess is OK.
Now it’s time to download the images:
import urllib.request
import tqdm
HOTDOG_PATH = './dataset/hotdogs/'
OTHER_PATH = ‘./dataset/other/'
def download_file(url: str, dest_dir: str):
base_name = os.path.basename(url)
dest_path = os.path.join(dest_dir, base_name)
try:
urllib.request.urlretrieve(url, dest_path)
except Exception as e:
print("Could not download file: {}, error: {}".format(base_name, e))
os.makedirs(HOTDOG_PATH, exist_ok=True)
for url in tqdm.tqdm(hotdog_image_urls):
download_file(url, HOTDOG_PATH)
os.makedirs(OTHER_PATH, exist_ok=True)
for url in tqdm.tqdm(other_image_urls):
download_file(url, OTHER_PATH)
A small surprise here: not all images included in the Google Open Images Dataset are still available at their original URLs:
Luckily, there are not too many of them. To keep things simple, let’s assume that the missing images won’t harm data distribution enough to worry.
Confirm that the images were properly saved to the selected destination ( ./dataset/hotdog and ./dataset/other)... and we are done with the download of training data.
Split Data Into Training and Test Datasets
In a real-life scenario, we would split the available data into training, validation, and test datasets.
In our case, Create ML will handle a random split into training and validation datasets. The test dataset would only be required for comparing the performance of the different models, which we are not planning to do.
Summary
In this article, you’ve learned how you can select and download annotated images from Google Open Images Dataset. Now we are ready to create and train a custom model using Create ML – see the next article.
Jarek has two decades of professional experience in software architecture and development, machine learning, business and system analysis, logistics, and business process optimization.
He is passionate about creating software solutions with complex logic, especially with the application of AI.





