Series Links
Table Of Contents
It has been a while since I have written a blog post or an article for that matter. There is a good reason for this, which is that I have started a new job, which is in a brand new domain for me (I have mainly worked in Fx), this job is a hedge fund / re-insurance firm. So I have been fairly tired. The reason I took this job, is that they asked me at the interview stage, how I would feel about us not using .NET for everything (which they had done until then), and what my thoughts were about using a stack made up of things like this:
I was frankly over the moon, I had just finished a book on Apache Spark, and REALLY want the chance to work with Scala / Cassandra, so I went for it.
This doesn't mean I don't do or LOVE .NET, heck I think .NET is the mutts nuts. There are however some great things going on out there in the non .NET / Microsoft space. Apache Spark is of particular interest to me.
This article will serve as a beginners guide to Apache Spark. In fairness Apache Spark has great documentation, which this article kind of just supplements. If however you have never heard of Apache Spark, you may like what you read, I certainly did the first time I read about it.
All examples and walkthroughs in this article and the demo app will be using Scala, as it is a nice modern OO/functional language.
You can grab a small IntelliJ IDEA Scala project from my GitHub repo : https://github.com/sachabarber/SparkDemo
This is what the creators of Apache Spark have to say about their own work.
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
http://spark.apache.org/docs/latest/index.html up on date 24/08/15
mmm want a bit more than just that, try this
At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.
A second abstraction in Spark is shared variables that can be used in parallel operations. By default, when Spark runs a function in parallel as a set of tasks on different nodes, it ships a copy of each variable used in the function to each task. Sometimes, a variable needs to be shared across tasks, or between tasks and the driver program. Spark supports two types of shared variables: broadcast variables, which can be used to cache a value in memory on all nodes, and accumulators, which are variables that are only “added†to, such as counters and sums.
Spark programming guide up on date 24/08/15
If you are the sort that likes diagrams, here is one that may help
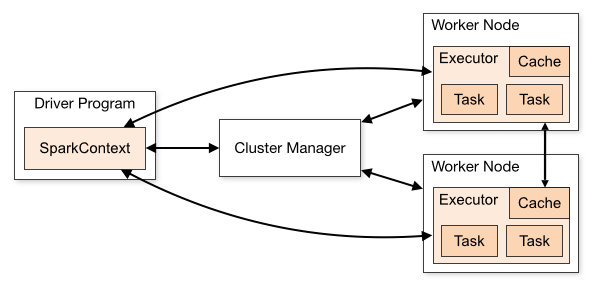
So that is what they have to say about it. Here are a couple of my own bullet points that may also help:
- Spark provides a common abstraction : Resilient Distributed Datasets (RDDs)
- Spark provides a LINQ like syntax that you can actually distribute across multiple worker nodes (LINQ like syntax across multiple nodes, think about that for a minute, that is like um WOW)
- Spark provides fault tolerance
- Spark provides same API for running locally as it does within a cluster which makes trying things out very easy
- Spark provides fairly simple API
- Very active community
- Put bluntly, It is a bloody brilliant product
The following diagram illustrates the current Apache Spark offering. Each one of the dark blue blocks in the diagram are a slightly different offering, for example:
- Spark SQL : Allows querying of structure data, such as JSON into RDDs (which means you can run RDD operations on JSON effectively)
- Spark Streaming : Allows the micro batching of data over time (window buffer, size buffer, sliding buffer etc. etc.), where the data received in that buffer is presented as a list. Which makes it very easy to deal with. Spark Streaming has many sources, such as
- Sockets
- Kafka
- Flume
- Zero MQ

Under pinning all of these is the common abstraction (Resilient Distributed Datasets (RDDs). So let's carry on and talk a but more about RDDs.
PS : In this article I WILL ONLY be covering Apache Spark basics and not each of the extra offerings above shown in the dark blue areas of the image.
Map Reduce
Map Reduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster. Conceptually similar approaches have been very well known since 1995 with the Message Passing Interface standard having reduce and scatter operations.
A Map Reduce program is composed of a Map() procedure that performs filtering and sorting (such as sorting students by first name into queues, one queue for each name) and a Reduce() procedure that performs a summary operation (such as counting the number of students in each queue, yielding name frequencies). The "Map Reduce System" (also called "infrastructure" or "framework") orchestrates the processing by marshaling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
https://en.wikipedia.org/wiki/MapReduce up on date 24/08/2015
Map Reduce typically runs on these Map/Reduce stages, which would typically require hardware for each stage.
Spark
At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.
http://spark.apache.org/docs/latest/programming-guide.html#overview up on date 24/08/2015
Spark runs entirely in memory on commodity grade hardware, and if the dataset can be fitted into memory is lightening fast, Spark claims that in this scenario it can be up to 100x faster than Map/Reduce. If you are persisting RDDs to disk Spark claim to be up to 10x faster that Map/Reduce.
Another areas where Spark wins out is the RDD Api, it is much richer than Map/Reduce operations.
Lets see a diagram which tries to illustrate the differences between Spark and Map/Reduce. It can be seen that in Map/Reduce there is a staged approach or Map/Reduce, repeat.
In Spark work is distributed to workers, each of which can do a portion of the work and then the results are consolidated and brought back to the driver program, or possibly persisted to disk.
For more discussions on the differences, Google is a good bet.
As previously stated one of the core concepts of working with Apache Spark is trying to work with RDDs. Taking some information (quite shamelessly) from the Apache Spark docs
RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset. For example, map is a transformation that passes each dataset element through a function and returns a new RDD representing the results. On the other hand, reduce is an action that aggregates all the elements of the RDD using some function and returns the final result to the driver program (although there is also a parallel reduceByKey that returns a distributed dataset).
All transformations in Spark are lazy, in that they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset (e.g. a file). The transformations are only computed when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently – for example, we can realize that a dataset created through map will be used in a reduce and return only the result of the reduce to the driver, rather than the larger mapped dataset.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist (or cache) method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it. There is also support for persisting RDDs on disk, or replicated across multiple nodes.
RDD Operations up on date 24/08/15
Lets examine a few of these
There are 2 ways to create RDDs, either by parallelizing some existing data in the driver program, or by using some of the factory methods on the SparkContext object. We will now see examples of both.
If we want to create an RDD from existing data (say from Cassandra), we could do something like this:
al data = Array(1, 2, 3, 4, 5)
val dataRdd = sc.parallelize(data)
This creates a RDD that can now be operator on in parallel. You can read more about this using the Spark documentation.
Spark also supports creating RDDs from external sources such as a hadoop file system, or from Amazon S3 file system, and Cassandra to name a few. If you just want to try something out locally you can even use a file system path. But remember this will not work if you choose to deploy to a cluster unless the file system object you have chosen is in the same place in all nodes in the cluster.
The setup I am using for this article is that I have a standalone scala application running on windows, and I am using Spark locally ONLY. That is I am not connecting to a Spark cluster, I am parallelizing only across the cores that my laptop has, which for me is 2. As a result of that I am able to use a local file system file to create an RDD, but this would likely not work if I was to try and run my code in a cluster, as a Spark cluster would need to be running on Linux and my Scala application is running on Windows, as such the format of the file system path is different. We will go into how to create a spark cluster later in the article. Granted not in very much detail, but I will lead you to the water, from there you may drink in the goodness of trying to setup a Spark cluster yourself.
Anyway enough chit chat, how do you create an RDD from one of these external sources.
val txtFileRdd = sc.textFile("data.txt")
This example simple creates an RDD from a text file.
Now that you have seen how to create RDDs, we can move along to see how to use the RDDs to perform transformation and carry out actions.
There are many RDD transformations, and for a full list of them you should consult the following page of the spark documentation : http://spark.apache.org/docs/latest/programming-guide.html#transformations
We will look at a few here, but essentially the name implies what is occurring when you use a transformation, you are essentially transforming the data in some way.
Description : Return a new dataset formed by selecting those elements of the source on which func returns true
Signature: filter(func)
val textFileRDD = sc.textFile(someTextFilePath, 2).cache()
val numAs = textFileRDD.filter(line => line.contains("a")).count()
Description : Return a new dataset formed by selecting those elements of the source on which func returns true
Signature: map(func)
val mapHoHo = textFileRDD.map(line => line + "HO HO")
println("HoHoHo line : %s".format(mapHoHo.first().toString()))
For more examples see this link : Spark transformations
There are many RDD actions, and for a full list of them you should consult the following page of the spark documentation :
http://spark.apache.org/docs/latest/programming-guide.html#actions
We will look at a few here, with actions you may think of them as performing some sort of final operation, such as count(), or first() both of which would need the full dataset to be in place (which may mean shuffling results back across the worker nodes). You may also find methods for saving an RDD such as saveAsTextFile(..), which would allow you save an RDD.
Description : Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data
Signature: collect()
val numAsArray = textFileRDD.filter(line => line.contains("a")).collect()
println("Lines with a: %s".format(numAsArray.length))
numAsArray.foreach(println)
println("Lines with a as Array: %s".format(numAsArray.getClass().getTypeName()))
Description : Return the first element of the dataset (similar to take(1))
Signature: first()
val firstLine = textFileRDD.first()
println("First Line: %s".format(firstLine))
You may choose to persist an RDD to IO. There are lots of options for this, and many things to consider. For more examples see this link : Spark actions
For more examples see this link : Spark actions
Typically within spark you will send a operation to a remote node for execution, where the node works on a separate copy of the data. Providing general purpose read/write variables across tasks/nodes would be inefficient. Spark does however provide 2 types of shared variables.
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner.
Broadcast variables are created from a variable v by calling SparkContext.broadcast(v). The broadcast variable is a wrapper around v, and its value can be accessed by calling the value method
http://spark.apache.org/docs/latest/programming-guide.html#shared-variables up on date 24/08/2015
Here is a quick example:
val broadcastVar = sc.broadcast(Array(1, 2, 3))
.....
broadcastVar.value
Accumulators are variables that are only “added†to through an associative operation and can therefore be efficiently supported in parallel. They can be used to implement counters (as in Map Reduce) or sums. Spark natively supports accumulators of numeric types, and programmers can add support for new types. If accumulators are created with a name, they will be displayed in Spark’s UI. This can be useful for understanding the progress of running stages (NOTE: this is not yet supported in Python).
An accumulator is created from an initial value v by calling SparkContext.accumulator(v). Tasks running on the cluster can then add to it using the add method or the += operator (in Scala and Python). However, they cannot read its value. Only the driver program can read the accumulator’s value, using its value method.
The code below shows an accumulator being used to add up the elements of an array:
http://spark.apache.org/docs/latest/programming-guide.html#shared-variables up on date 24/08/2015
Here is a quick example:
val accum = sc.accumulator(0, "My Accumulator")
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
var accuulatedValue = accum.value
There are certain operations that will cause Spark to perform what is known as a "Shuffle". What this refers to is the job of reading all the data from all the partitions. This is a costly thing to, as it involves disk I/O, network I/O, serialization.
Operations which can cause a shuffle include repartition operations like repartition and coalesce, ‘ByKey operations (except for counting) like groupByKey and reduceByKey, and join operations like cogroup and join.
You can read more about this here : shuffle operations
One of the most important capabilities in Spark is persisting (or caching) a dataset in memory across operations. When you persist an RDD, each node stores any partitions of it that it computes in memory and reuses them in other actions on that dataset (or datasets derived from it). This allows future actions to be much faster (often by more than 10x). Caching is a key tool for iterative algorithms and fast interactive use.
You can mark an RDD to be persisted using the persist() or cache() methods on it. The first time it is computed in an action, it will be kept in memory on the nodes. Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.
Persisting RDDs up on date 24/08/15
Apache Spark itself is quite large, luckily we can get up and running with just a bunch of JAR files. The easiest way to start out with Apache Spark (at least in my opinion) is to do the following
- Download SBT (it's free)
- Download the 1.8 JDK (or later) (it's free)
- Download IntelliJ IDEA Community Edition (it's free)
You can of course download the actual Apache Spark Windows installer, which will dump a bunch of stuff in a folder of your choosing. The thing is the Apache Spark team say that Apache Spark runs on Windows, but it doesn't run that well. You would typically run it on a Linux Cluster. We will talk more about this later. But for now just remember that Apache Spark really does run MUCH better on a Linux VM/Box/Cluster, and you should ensure you do that for a real environment. For messing around you could use Windows, which we will also talk about later.
You will need to install the simple build tool, which you can grab from here:
http://www.scala-sbt.org/
If you have not heard of SBT or do not know what it is, you can think of it as a build tool and package management tool, in some ways it is similar to Nuget, though SBT actually uses Scala as the grammar/DSL in which to express your build requirements.
You may use it to scaffold a Scala project and also download a Scala project's dependencies. We will see more on this later.
Apache Spark uses one of the following 3 programming languages
- Java
- Scala
- Python
For the top 2 we obviously need the JDK. So we need to grab it. You can grab it from the Oracle web site:
Java SDK Downloads
The typical Java 8 SDK installation should be fine, pick the one that you need for your environment
You can download a free copy of IntelliJ IDEA from here : https://www.jetbrains.com/idea/download/
Like I have stated in this article already you would likely not run Apache Spark cluster on Windows, however you may want to run the driver program on windows. I wanted to do this, and I got a weird error to do with a missing "winutils.exe" file.
I did a bit of Googling and it is quite easy to fix, you can get the fix from the chaps web site shown below, where he states the exact exception you may see.
.....and you will see the following exception:
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
The reason is because spark expect to find HADOOP_HOME environment variable pointed to hadoop binary distribution, .........
Let’s download hadoop common binary, extract the downloaded zipped file to ‘C:\hadoop’ , then set the HADOOP_HOME to that folder.
http://ysinjab.com/2015/03/28/hello-spark/ up on date 24/08/2015
The download you need to fix this is here : http://www.srccodes.com/p/article/39/error-util-shell-failed-locate-winutils-binary-hadoop-binary-path
And the steps to follow are as stated above
This section of the article is really the only original part of the entire article. In this section I will discuss how I myself got up and running as follows:
- Spark in local mode on Windows
- No cluster
- Using Scala through IntelliJ IDEA
The thing with this section is if you need to change to using a cluster, all you need to change is the master node connection string details and the rest will be the same.
In this section we will create a new Apache Spark application which has the following features
- Runs on Windows through IntelliJ IDEA
- Demonstrates the usage of SBT to manage dependencies
- Demonstrates a few RDD transformations
- Demonstrates a few RDD actions
We need to create a new project
CLICK FOR LARGER IMAGE
We then need to choose SBT project
CLICK FOR LARGER IMAGE
You should choose the following settings when you are creating the project
CLICK FOR LARGER IMAGE
NOTE : It is quite important to pick Scala version of 2.10.5, as the current released build (at time of writing) of Apache Spark was v1.4.1, which doesn't support Scala 2.11.x, so you need to make sure you target Scala 2.10.5.
Once you have done that, you need to wait a while to let SBT to do a few things, after a while you should then see this sort of project structure
So we now have a default SBT project. This is good, but now we need to get the actual Spark JAR files. This is done by modifying the main build.sbt file
So open that up, and change its contents to this:
name := "SparkDemo"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.4.1"
Next open up the SBT Window, as shown below
Click on the refresh icon
This will fetch all the dependencies that are needed for the dependencies you specified in the build.sbt file above.
This will take a LONG time, just let it do its thing.
When this is done you should do 2 things:
- Check your SBT cache contains the Spark JARs. Which is this directory "C:\Users\YOUR_USER\.ivy2\cache"
- You should make sure that the SBT cache is used for the actual IntelliJ IDEA as a package source (similar to what you do with Nuget and Visual Studio is you have setup your own Nuget store)
This is done as follows from within IntelliJ IDEA.
Then follow steps below, where you would add stuff from your own .ivy2 cache directory (for example C:\Users\YOUR_USER\.ivy2\cache")
CLICK FOR LARGER IMAGE
Once you have gone through the pain of downloading the whole heap of dependencies you need to run Spark, you should be able to create a simple driver program something like the following:
The only thing that I have not explained so far in the code below, is the line
conf.setMaster("local[2]")
What this does, it runs spark locally using 2 cores (which is all my laptop has). This line is what you would change if you were running the driver program against a cluster.
You can read more about this at this Url : Spark Master Urls It's an old page but the data is still valid
Anyway here is the example driver program
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val someTextFilePath = "C:/Temp/SomeTextFile.txt"
val conf = new SparkConf().setAppName("Simple Application")
conf.setMaster("local[2]")
val sc = new SparkContext(conf)
val textFileRDD = sc.textFile(someTextFilePath, 2).cache()
val numAs = textFileRDD.filter(line => line.contains("a")).count()
val numBs = textFileRDD.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
val mapHoHo = textFileRDD.map(line => line + "HO HO")
println("HoHoHo line : %s".format(mapHoHo.first().toString()))
val numAsArray = textFileRDD.filter(line => line.contains("a")).collect()
println("Lines with a: %s".format(numAsArray.length))
numAsArray.foreach(println)
println("Lines with a as Array: %s".format(numAsArray.getClass().getTypeName()))
val firstLine = textFileRDD.first()
println("First Line: %s".format(firstLine))
readLine()
}
}
You can carry on reading more about these things using these links
Anyway that is all I wanted to say this time, I hope that some of you that may have not come across these things before got a little something out of it


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






