A hierarchical object is built from relationships between categories and their parents. It is used in a classifier, detecting if an article belongs to possibly far parent category.
Introduction
The value of Wikipedia as a unique source for data mining cannot be overemphasized. XML dumps of the whole textual contents of it allow every researcher to discover hidden relationships between objects and patterns in history and society.
The necessary stage of this process is filtering information of interest. In simplest cases, a search of keywords may be used. However, the credibility of such approach is low because of ignorance of keyword meaning in a phrase and impossibility of stating sets of keywords, describing the subject closely. Wikipedia has an intrinsic mechanism for organizing its information. It is categorization. Almost every page is required pertaining to at least one category. However, classification, based on this fact, is not "easy to use" in practice.
In this article, we:
- use code and results of our previous work to build a pretty complicated object, representing the hierarchy of categories from Wikipedia.
- develop classifier to determine if a page belongs to a category or to any of its children.
- provide GUI application, demonstrating usage of the hierarchy of categories and performing proper classification.
Background
It is good to understand the process of creation of Wikipedia pages and their categorization. Download of complete "pages‐articles" XML dump file is required. We used enwiki‐20160305‐pages‐articlesmultistream.xml.bz2 ﴾about 12.7G archive containing 52.5G file for the spring of 2016). Now it is not available at its original location. Similar newer files may be downloaded from Wikipedia Download Page Wikipedia Download Page, for instance. Then, the project from our previous article, "Parsing Wikipedia XML dump" is needed to extract the real data.
C# code uses various collections, some LINQ, and RegEx.
Categorization in Wikipedia
To start, let's take a very brief excursus to the Wikipedia's way of categorization.
Every Web page returned by Wikipedia shows a list of categories to which it belongs. They are listed in the "Categories" box at the bottom of each page. For instance, page "Algorithm" belongs to "Algorithms", "Mathematical logic", and to "Theoretical computer science" categories.
We call them as "immediate parents" and, correspondingly, treat the proper page as an "immediate child". Some exceptions apply. For instance, the very basic categories, like "Contents", have no parents. Actual articles are stored under "Articles" category. Currently, there are more than a million categories, even not including so called "hidden" categories and categories of special usage.
Each immediate parent category usually has its own immediate parents. For instance, "Mathematical logic" is an immediate child of "Logic", "Fields of Mathematics" and "Philosophy of mathematics". This way, parent‐child relationships may form long chains.
Hierarchy of categories, generated by such approach, is not a simple tree structure, because each page usually has several parents, at least. The structure is much more complicated. Ideally, it should be directed acyclic graph. Simply speaking, there should be no cycles and no cases when a child appears in the list of its own parents. In reality, there are many cases of such cycles and both ways parent‐child relationship. Some of them are pretty short, others span through multiple levels. Wikipedia suggests a tool revealing them. Examples:
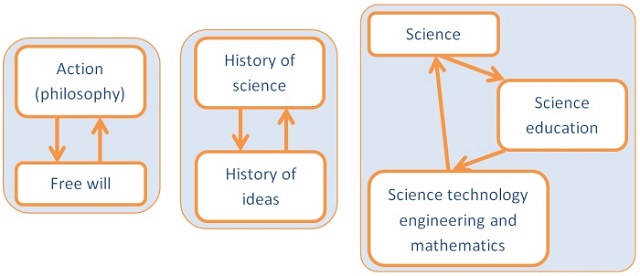
Boxes on this image are clickable. Arrows denote relationship from parent to child.
Wikipedia changes with time, thus some of such cases may disappear. But it is difficult to imagine that all of them may be eliminated. Developing of an automatic classifier, based on the hierarchy of categories, we should take this very carefully.
Another thing that should be taken into account is that any error in the relationship of a category may have much more significant effect than just an error in a regular page because search may return a large set of false positives ﴾when a wrong category is defined as child﴿ or false negatives ﴾when the true child is missed﴿. Choice of parents almost completely is a responsibility of Wikipedia contributors. A couple of examples of related problems will be given later. Thus researchers should not rely only on formal approach querying the hierarchy. They must be ready to use common sense, make enough statistical selection checks and choose the most reasonable queries.
Fortunately, the situation is not as bad as it may appear at first glance. Everyone may select several categories by typing "Category:[SomeCategory]" in Wikipedia search box and walk through parents or children to ensure how reasonably the chain is built.
Researcher's Goal
Building the hierarchy object is not an end itself. The practical task is in extracting information, related to the subject of research. In many cases, the subject may be described in terms of categories. Let's consider an example.
Suppose our study is focused on people in sport, mentioned in the Wikipedia. Filtering the list of categories, we find category "Sportspeople" existing. If pages with their parent categories had been extracted as we described earlier, then we have a lookup table like:
| Name | Born | Died | Age | Count | Parent categories |
| Moonlight Graham | 1879 | 1965 | 86 | 45 | ...|Sportspeople from Fayetteville, North Carolina|American physicians|...|New York Giants ﴾NL﴿ players|University of Maryland, Baltimore alumni|... |
| Lou Thesz | 1916 | 2002 | 86 | 198 | ..|American male professional wrestlers|American people of Hungarian descent|Professional Wrestling Hall of Fame and Museum|... |
| Marc Perrodon | 1878 | 1939 | 61 | 9 | ..|People from Vendôme|French male fencers|Olympic fencers of France|Fencers at the 1908 Summer Olympics|... |
The first row explicitly mentions word "Sportspeople" in immediate parents. Thus classification seems extremely obvious. However, it is not, because the actual parent is "Sportspeople from...", not "Sportspeople". A single word may have any meaning in the whole category name. "Sportspeople from Fayetteville, North Carolina" is a child category of "Sportspeople", indeed, but having common word is not a credible evidence of a parent‐child relationship in the general case.
Classification of the second and the third row is clear for human because we know that wrestlers and fencers ﴾especially, participated in Olympic games﴿ are sportspeople. Computer does not know this a priori. That's why knowledge of all children of the category of interest is needed for automatic classification. The page is related to the subject category only if a child of it is exactly present in page's immediate category parents.
Let's build graph of categories hierarchy and a classifier, based on it.
Hierarchy Class
Two dictionaries form the core of Hierarchy class:
public Dictionary<string, CategoryData> CategoriesByName;
public Dictionary<int, string> CategoriesByIndex;
The first one allows quick access to category properties by name, the second one retrieves category name by index. Category properties are of CategoryData class:
public class CategoryData
{
public HashSet<int> Parents = new HashSet<int>();
public HashSet<int> Children = new HashSet<int>();
public int Index;
public int Level;
public CategoryData(int index, int level = -1)
{
Index = index;
Level = level;
}
}
We introduce Level to measure how far a category is relatively to the top category. The top category may be any. However, to include the whole contents of Wikipedia, it should be set to "Contents" or "Articles". The Level of the top category is zero by definition. The Level of every of its immediate children is one. The Level of their children is two and so on. Before calculating levels, we need to load all categories with their immediate parents. For each category, they are stored in Parents member of CategoryData. HashSet<int> is used because an order of members does not matter and no duplicates guaranteed.
If category A is an immediate parent of category B, then B is an immediate child of A. Quick access to children is available through Children member of CategoryData.
Constructor of Hierarchy class reads tab delimited file, containing categories names and names of their parents, into these dictionaries. The file may contain optional "Level" column:
public Hierarchy(string categoryParentsPath)
If the input file contains Levels column, a level for each category is set to the value from file. Otherwise, levels are calculated at the end of this method relatively to "Articles", if such exists. If not, subsequent usage
requires caller to execute.
public void SetLevelsFromTop(string topCategory)
To save Hierarchy object ﴾or its subgraph, after call to SetLevelsFromTop(...)﴿, use Save(...):
public void Save(string path)
The saved file of smaller size may be used on input, if just a subgraph is needed.
To retrieve all parents or children ﴾not only immediate﴿, use AllRelatives(...):
public HashSet<int> AllRelatives(int index, bool direction)
Proper calculations may be relatively long. To avoid "freezing" of GUI, this method is decorated by wrappers around asynchronous tasks, returning their results:
private async Task<HashSet<int>> AllRelativesTask(int index, bool direction)
{
return await Task.Run(() => GetAllRelatives(index, direction)).ConfigureAwait(false);
}
private HashSet<int> GetAllRelatives(int index, bool direction)
{
HashSet<int> result = new HashSet<int>();
HashSet<int> relatives = new HashSet<int>();
relatives.Add(index);
while (relatives.Count > 0)
{
result.UnionWith(relatives);
relatives = ValidRelatives(relatives, direction);
relatives.ExceptWith(result);
}
return result;
}
This method implements non‐recursive walk through the graph in a given direction. Using HashSet class takes care of breaking cycles. Loop is finite because of finite number of categories and absence of duplicates in the result.
ValidRelatives(...) collects acceptable immediate relatives from all nodes in HashSet<int> categories collection:
private HashSet<int> ValidRelatives(HashSet<int> categories, bool direction)
{
HashSet<int> result = new HashSet<int>();
foreach (int i in categories)
{
HashSet<int> validRelatives = ValidRelatives(i, direction);
result.UnionWith(validRelatives);
}
return result;
}
Meaning of HashSet<int> ValidRelatives(int index, bool direction) will be explained after considering the following example of real‐world child‐parent relationships:

Though there's no guarantee that related content of Wikipedia won't be changed, it's good to track this chain, which is quite typical. Just click on areas of image and look at proper parent category at the bottom of opened Web page.
It is absolutely senseless that "Sports competitions" appears as child of "Abstraction" and even of "Animal anatomy". To understand why this happens, let's pay attention to levels of categories.
The first questionable relation is Competition ﴾Level 3﴿ <‐ Difference ﴾4﴿. The second one is Thought ﴾3﴿ <‐ Mind ﴾5﴿ <‐ Brain ﴾6﴿. Normally, parent should be located upper in the hierarchy and have lower value of Level than child has. The chain above demonstrates violation of this rule.
To minimize risk of such senseless results, we apply restrictions on possible relations between parent and child levels, using ParentLevelAllowance property:
public enum ParentLevelAllowanceType { LowerOnly = 0, SameOrLower = 1, Any = 2 };
private ParentLevelAllowanceType parentLevelAllowance =
ParentLevelAllowanceType.SameOrLower;
and calculate ValidRelatives this way:
public HashSet<int> ValidRelatives(int category, bool direction)
{
int level = Level(category);
switch (ParentLevelAllowance)
{
case (ParentLevelAllowanceType.LowerOnly) :
{
return direction ? new HashSet<int>(Children(category).Where(x => Level(x) > level))
: new HashSet<int>(Parents(category).Where(x => Level(x) < level));
}
case (ParentLevelAllowanceType.SameOrLower) :
{
return direction ? new HashSet<int>(Children(category).Where(x => Level(x) >= level))
: new HashSet<int>(Parents(category).Where(x => Level(x) <= level));
}
default:
{
return direction ? new HashSet<int>(Children(category))
: new HashSet<int>(Parents(category));
}
}
}
LowerOnly and SameOrLower, studying categories of interest. In our experience, SameOrLower is the best default. LowerOnly lowers a number of false positives by reducing the total number of detections.
To illustrate the problem, let's assume that a research is focused on people in science. "Science" category seems good choice for start. In case LowerOnly it produces a list of about 40000 children. Though there may be exceptions, we did not find any non‐scientific children ﴾according to our picture of that﴿. At the same time, it is easy to find that the list is not as complete as necessary. SameOrLower generates much larger set with many bogus children, containing something that we don't want:
These observations lead to the conclusion that study of parent‐children chains is important and that "Science" category is not a good choice for research, stated above. Much better choice is "Scientists" category. It brings very accurate results, especially when applied to the list of people. GUI utility may be used to prove that.
GUI Utility
The utility is developed to illustrate the usage of Hierarchy class. It allows performing some researches. It was used to produce all examples above. The file, containing categories and their parents, extracted from full Wikipedia dump, is required on input.
Main window groups three tasks. Each one is represented by the proper tab. Tab, shown above, allows searching names of categories, matching substring or regular expression. This search is useful when a researcher does not know names of categories matching the subject of interest most closely.
Sample output is as follows:
This grid and the ones shown below are sortable and searchable. Names of categories are clickable. Click on a cell in the first column opens proper Wikipedia Web page.
The second tab serves for listing parents and children of selected category:
Clicking "Parents" button returns four parents:
Clicking "Children" button brings in this case a list of 589 categories:
"Explain" item of popup menu reveals chains ﴾possible paths in the graph, not necessarily the shortest﴿ of parent‐child relationships. For selected categories, they are:
Studying of such chains is an important part of designing most appropriated queries, which, for instance, exclude some subcategories from paths.
GUI, presented here, works with queries containing just a single category. Programming queries, containing simple logical expressions on categories seems straightforward.
The last tab illustrates classifier which filters pages belonging to specified category from list of Wikipedia pages or from biographical pages, created in our previous work:
Here's a random selection, containing, say, 10% or even 0.1% of the input file may be used. This saves time selecting random samples for manual statistical verification of output:
Happy Wikipedia mining!
History
- 1st June, 2016: Original publication
- 3rd June, 2016: Minor changes
- Fixed a couple of typos and spelling mistakes
- Several screenshots resized to fit layout better
Programmer, developer, and researcher. Worked for several software companies, including Microsoft.
PhD in Theoretical Physics, D.Sc. in Solid State Physics.
Enjoys discovering patterns in nature, history and society, which break public opinion or are hidden from it.
Professor Vladimir Shatalov works on National Technical University of Ukraine 'Kyiv Polytechnic Institute', Slavutych branch, teaches students to Computer Science. Research interests include Data Mining, Artificial Intelligence, Theoretical Physics and Biophysics.
Research activity also concerns investigations of mechanisms of non-thermal electromagnetic and acoustic fields impacts on bio-liquids, effects of irradiations on physical and chemical properties of water.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









