Here we evaluate and improve our deep network performance.
Introduction
The availability of datasets like DeepFashion open up new possibilities for the fashion industry. In this series of articles, we’ll showcase an AI-powered deep learning system that can revolutionize the fashion design industry by helping us better understand customers’ needs.
In this project, we’ll use:
- Jupyter Notebook as the IDE
- Libraries:
- A custom subset of the DeepFashion dataset — relatively small to reduce the computational and memory overhead
We are assuming that you are familiar with the concepts of deep learning, as well as with Jupyter Notebooks and TensorFlow. If you’re new to Jupyter Notebooks, start with this tutorial. You are welcome to download the project code.
In the previous article, we evaluated and improved our deep network performance. In this article, we’ll work on building, training, and testing a Generative Adversarial Network (GAN) — the network we’ll then use to generate new clothing images and designs.
The Power of Predicting New Fashion Images
AI can help us to not only predict the category of a clothing item, but also to create computer-generated images of similar-looking items. This can be pretty handy for retailers and fashion designers who strive to create personalized clothes or predict broader fashion trends.
Until the creation of GANs, generating realistic fashion images was a challenging task due to the images' high volume of data. Images tend to be high resolution, resulting in many pixels. Plus, each pixel represents three channel values: red, blue, and green (RGB). GANs provide researchers with a viable method of generating and verifying all this data.
Building a GAN
A GAN is a popular model for unsupervised machine learning where two neural networks — a generator and a discriminator — interact with each other. The generator’s role is to generate images out of random noise it takes as input. The discriminator’s task is to detect whether these generated images are fake or real (by comparing them to the images in a dataset). This process continues for several epochs until the discriminator loss between fake and real achieves its minimum. As the loss reaches the minimum, the generator becomes sufficiently skilled in generating images similar to those in the original dataset.
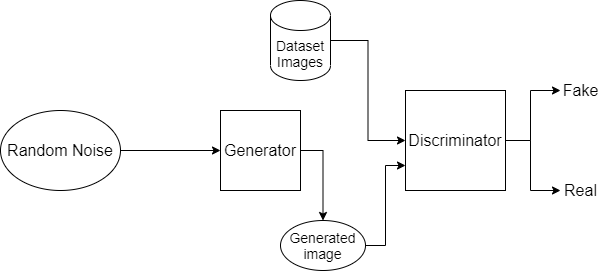
Building a GAN will include the following stages:
- Initializing the network parameters and loading data
- Building the generator
- Building the discriminator
We’ll use the Pytorch library for building our GAN. This library is fast, and it doesn’t require a lot of computational power.
To install Pytorch with CUDA10 on Conda:
conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch
Initializing GAN Parameters and Loading Data
The two convolutional neural networks (CNNs) that constitute a GAN include convolution, batch normalization, and ReLU layers for the discriminator, and deconvolution, batch normalization, and ReLU layers for the generator.
Before starting to build our generator and discriminator networks, let’s set some parameters and load the fashion image dataset that will be used to train and test the network.
First, we impot some dependencies.
from __future__ import print_function
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
Next, we set some random seeds to achieve reproducibility:
manualSeed = 999
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
Then, we set some important parameters, such as the number of feature maps, input image size, batch size, number of epochs, and learning rate.
dataroot = r"C:\Users\abdul\Desktop\ContentLab\P2\DeepFashion\Train"
workers = 2
batch_size = 128
image_size = 64
nc = 3
nz = 100
ngf = 64
ndf = 64
num_epochs = 40
lr = 0.0002
beta1 = 0.5
ngpu = 1
Now we can load our data using dataloader and show a sample of that data.
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))

Finally, we’ll use the function below to initialize weights for both the generator and discriminator networks.
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
Building a Generator from Scratch
The generator CNN consists of transposed convolutional layers, batch norm layers, and ReLU activations. The input is a latent vector, z, which is drawn from a standard normal distribution, and the output is a 3 x 64 x 64 pixels RGB image.
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
Now, we create the netG generator and show its structure.
netG = Generator(ngpu).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
netG.apply(weights_init)
print(netG)
Building a Discriminator from Scratch
Our discriminator will be called netD, and it will be composed of strided convolution layers, LeakyReLU activations, and batch norm layers. Its input will be a 3 x 64 x 64 input image, and its output will be the scalar probability of the input being from the real dataset.
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
netD = Discriminator(ngpu).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
netD.apply(weights_init)
print(netD)
Initializing Loss and Optimizer for GAN
Before starting to train our GAN, we’ll set up its loss functions and optimizer. In GANs, we usually use binary cross-entropy as a loss function because we have two classes in the output: Fake (0) and Real (1). We’ll use the Adam optimizer with a learning rate of 0.0002 and Beta1 of 0.5.
criterion = nn.BCELoss()
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_label = 1.
fake_label = 0.
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
Next Steps
In the next article, we’ll show you how to train the GAN for fashion design generation. Stay tuned!
Dr. Helwan is a machine learning and medical image analysis enthusiast.
His research interests include but not limited to Machine and deep learning in medicine, Medical computational intelligence, Biomedical image processing, and Biomedical engineering and systems.





