Here we’ll continue to tackle large models, this time for Natural Language Processing (NLP) tasks with PyTorch and Transformers.
Introduction
Container technologies, such as Docker, simplify dependency management and improve portability of your software. In this series of articles, we explore Docker usage in Machine Learning (ML) scenarios.
This series assumes that you are familiar with AI/ML, containerization in general, and Docker in particular.
In the previous article of this series, we have run inference on sample images with TensorFlow using a containerized Object Detection API environment. In this one, we’ll continue to tackle large models, this time for Natural Language Processing (NLP) tasks with PyTorch and Transformers. You are welcome to download the code used in this article.
In subsequent articles of this series, we’ll serve the inference model via a Rest API. Next, we’ll debug the Rest API service running in a container. Finally, we’ll publish the created container in the cloud using Azure Container Instances.
Containers and Large Models
Containers use for Machine Learning is rather straightforward as long as you work with relatively small models. The simplest approach is to treat models as part of your code and add them to the container during build. This gets more complicated as the models become larger. Quite often, models can measure hundreds of megabytes or even more. Adding so much weight to an image would increase its size and build time. Also, if you run your code in a horizontally scaled cluster, this additional weight would be multiplied by the number of running containers.
As a general rule, you should not include in your image anything that can be easily shared between container instances. During development, shared files can be handled by mapping a local folder to a container volume. That’s what we did in the previous article for the Object Detection API model. In production, this may not be possible though, especially if you plan to run your containers in the cloud.
The preferred solution in such cases is to rely on Docker volumes. This approach has some drawbacks though. Persisting and sharing anything between containers introduces additional dependencies. The same container may behave differently depending on what is already stored in the persisted volume. Besides, you cannot store anything in the volume until the container is already running (not during the build).
Dockerfile for Transformers
Hugging’s Face Transformers is a very popular library for handling Natural Language Processing (NLP) tasks. It supports many modern NLP model architectures and ML frameworks, including both TensorFlow and PyTorch. We have already used TensorFlow a few times – let’s go with the PyTorch version for a change.
Our Dockerfile will be fairly simple:
FROM pytorch/pytorch:1.6.0-cuda10.1-cudnn7-runtime
ENV DEBIAN_FRONTEND=noninteractive
ARG USERNAME=mluser
ARG USERID=1000
RUN useradd --system --create-home --shell /bin/bash --uid $USERID $USERNAME \
&& mkdir /home/$USERNAME/.cache && chown -R $USERNAME /home/$USERNAME/.cache
COPY requirements.txt /tmp/requirements.txt
RUN pip install -r /tmp/requirements.txt \
&& rm /tmp/requirements.txt
USER $USERNAME
COPY --chown=$USERNAME ./app /home/$USERNAME/app
WORKDIR /home/$USERNAME/app
ENV LC_ALL=C.UTF-8
ENV LANG=C.UTF-8
ENTRYPOINT ["python", "nlp.py"]
Apart from the base image, not much is different from the previous article. The official PyTorch base image provides us with everything we need, and is still smaller than TensorFlow-GPU one.
This time, we don’t need any additional system dependencies, so we can avoid the apt-get command. Note the mkdir /home/$USERNAME/.cache command in the first RUN statement. During the container execution, we’ll mount a Docker volume to this path for the downloaded PyTorch models.
We create this folder explicitly to enable setting access permissions when we build the image. These permissions will carry over to the volume mounted during the container execution.
The requirements.txt file is extremely compact as well. It contains a single line:
transformers==4.3.2
The most complex part of our solution is stored in the nlp.py script. It is set as an entrypoint to our container, and is available in the code download archive.
Composing Containers
To simplify volume creation and mounting, this time we’ll use docker-compose to build and run our container. If you are using the Docker desktop, you should have it already installed. In the case of Docker Server on Linux, you may need to install it.
Note that, in the recent Docker versions, you can use the docker compose command instead of docker-compose. However, to our surprise, we’ve noticed that the results these two commands had brought weren’t always the same. So we’ll stick to docker-compose in this article series.
Now, let’s create a short docker-compose.yml file in the same directory where our Dockerfile resides:
version: '3.7'
volumes:
mluser_cache:
name: mluser_cache
services:
mld07_transformers:
build:
context: '.'
dockerfile: 'Dockerfile'
image: 'mld07_transformers'
volumes:
- mluser_cache:/home/mluser/.cache
We instruct docker-compose to do two things here: to create the mluser_cache volume and to mount it to the /home/mluser/.cache path when the container is running. Apart from that, the file defines the image name and the build context.
Building Container
With docker-compose, the command to build the container will be slightly different than in the previous article:
$ docker-compose build --build-arg USERID=$(id -u)
With all basic parameters included in the docker-compose.yml configuration, all we need here is to pass the USERID value. Because this time we won’t mount a local folder as the container volume, the --build-arg USERID attribute could be safely ignored. In fact, when running on Windows, you can always ignore it. We only keep it here to ensure consistent permissions for the subsequent articles.
Running Container
Now that the container is built, let’s check if it works. We’ll start with a question-answering task:
$ docker-compose run --user $(id -u) mld07_transformers \
--task="qa" \
--document="We have considered many names for my dog, such as: Small, Black or Buster. Finally we have called him Ratchet. It is quite an unusual name, but the dog's owner named Michael picked it." \
--question="What is the name of my dog?"
We were deliberately tricky here: throwing multiple "names" in the document; however, the model handled it pretty well:
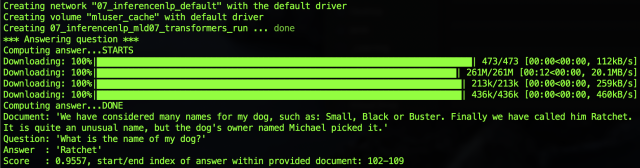
The first time the model was executed, a related model was downloaded and stored in the .cache folder mapped to our mluser_cache volume.
To inspect the volume size, we can use the following command:
$ docker system df -v
Local Volumes space usage should display:

To make sure that the model data is persisted, we can run the same docker-compose run command as we did previously, with a slightly different result:
This time the model was already in the .cache folder, so it wasn’t downloaded again.
Feel free to experiment with other models for the different NLP tasks included in the downloaded nlp.py script. Note that each of these models needs to be downloaded the first time it is used, and some of them exceed 1 GB in size.
Summary
Our inference model for NLP tasks is working, and the downloaded models are saved to the persisted volume. In the next article, we’ll modify our code to expose the same logic via a Rest API service. Stay tuned!
Jarek has two decades of professional experience in software architecture and development, machine learning, business and system analysis, logistics, and business process optimization.
He is passionate about creating software solutions with complex logic, especially with the application of AI.





