What is .NET Jupyter Notebook
For those who used Notebook from other programming languages like Python or R, this would be an easy task. First of all, the Notebook concept provides a quick, simple and straightforward way to present a mix of text and $ \Latex $, source code implementation and its output. This means you have a full-featured platform to write a paper or blog post, presentation slides, lecture notes, and other educated materials.
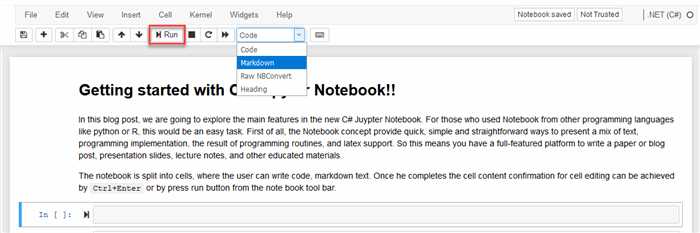
The notebook consists of cells, where a user can write code or markdown text. Once he completes the cell content confirmation for cell editing can be achieved by Ctrl+Enter or by press run button from the notebook toolbar. The image below shows the notebook toolbar, with a Run button. The popup combo box shows the type of cell the user can define. In the case of text, Markdown should be selected, for writing source code the cell should be Code.
To start writing code to C# Notebook, the first thing we should do is install NuGet packages or add assembly references and define using statements. In order to do that, the following code installs several nuget packages, and declare several using statements. But before writing code, we should add a new cell by pressing + toolbar button.
The first few NuGet packages are packages for ML.NET. Then we install the XPlot package for data visualization in .NET Notebook, and then we install a set of Daany packages for data analytics. First, we install Daany.DataFrame for data exploration and analysis, and then Daany.DataFrame.Ext set of extensions for data manipulation used with ML.NET.
#r "nuget:Microsoft.ML.LightGBM"
#r "nuget:Microsoft.ML"
#r "nuget:Microsoft.ML.DataView"
#r "nuget:XPlot.Plotly"
#r "nuget:Daany.DataFrame"
#r "nuget:Daany.DataFrame.Ext"
using System;
using System.Linq;
using Daany;
using Daany.Ext;
using XPlot.Plotly;
using Microsoft.ML;
using Microsoft.ML.Data;
using Microsoft.ML.Trainers.LightGbm;
The output for the above code:

Once the NuGet packages are installed successfully, we can start with data exploration. But before this, declare few using statements:
We can define classes or methods globally. The following code implements the formatter method for displaying Daany.DataFrame in the output cell.
using Microsoft.AspNetCore.Html;
Formatter<DataFrame>.Register((df, writer) =>
{
var headers = new List<IHtmlContent>();
headers.Add(th(i("index")));
headers.AddRange(df.Columns.Select(c => (IHtmlContent) th(c)));
var rows = new List<List<IHtmlContent>>();
var take = 20;
for (var i = 0; i < Math.Min(take, df.RowCount()); i++)
{
var cells = new List<IHtmlContent>();
cells.Add(td(df.Index[i]));
foreach (var obj in df[i])
{
cells.Add(td(obj));
}
rows.Add(cells);
}
var t = table(
thead(
headers),
tbody(
rows.Select(
r => tr(r))));
writer.Write(t);
}, "text/html");
For this demo, we will use the famous Iris data set. We will download the file from the internet, load it by using Daany.DataFrame, and display few first rows. In order to do that, we run the following code:
var url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data";
var cols = new string[] {"sepal_length","sepal_width",
"petal_length", "petal_width", "flower_type"};
var df = DataFrame.FromWeb(url, sep:',',names:cols);
df.Head(5)
The output looks like this:
As can be seen, the last line from the previous code has no semicolon, which means the line should be displayed in the output cell. Let’s move on, and implement two new columns. The new columns will be sepal and petal area for the flower. The expression we are going to use is:
$$ PetalArea = petal_width \cdot petal_length;\ SepalArea = sepal_width \cdot sepal_length; $$
As can be seen, the $\LaTeX$ is fully supported in the notebook.
The above formula is implemented in the following code:
df.AddCalculatedColumn("SepalArea",
(r, i) => Convert.ToSingle(r["sepal_width"]) * Convert.ToSingle(r["sepal_length"]));
df.AddCalculatedColumn("PetalArea",
(r, i) => Convert.ToSingle(r["petal_width"]) * Convert.ToSingle(r["petal_length"]));
df.Head(5)
The data frame has two new columns. They indicate the area for the flower. In order to see basic statistics parameters for each of the defined columns, we call Describe method.
df.Describe(false)
From the table above, we can see the flower column has only 3 values. The most frequent value has a frequency equal to 50, which is an indicator of a balanced dataset.
Data Visualization
The most powerful feature in Notebook is a data visualization. In this section, we are going to plot some interesting charts.
In order to see how sepal and petal areas are spread in 2D plane, the following plot is implemented:
var faresHistogram = Chart.Plot(new Graph.Histogram(){x = df["flower_type"],
autobinx = false, nbinsx = 20});
var layout = new Layout.Layout(){title="Distribution of iris flower"};
faresHistogram.WithLayout(layout);
display(faresHistogram);
The chart is also an indication of a balanced dataset.
Now let's plot areas depending on the flower type:
var chart = Chart.Plot(
new Graph.Scatter()
{
x = df["SepalArea"],
y = df["PetalArea"],
mode = "markers",
marker = new Graph.Marker()
{
color = df["flower_type"].Select
(x=>x.ToString()=="Iris-virginica"?1:(x.ToString()=="Iris-versicolor"?2:3)),
colorscale = "Jet"
}
}
);
var layout = new Layout.Layout()
{title="Plot Sepal vs. Petal Area & color scale on flower type"};
chart.WithLayout(layout);
chart.WithLegend(true);
chart.WithLabels(new string[3]{"Iris-virginica","Iris-versicolor", "Iris-setosa"});
chart.WithXTitle("Sepal Area");
chart.WithYTitle("Petal Area");
chart.Width = 800;
chart.Height = 400;
display(chart);
As can be seen from the chart above, flower types are separated almost linearly, since we used petal and sepal areas instead of width and length. With this transformation, we can get a 100% accurate ml model.
Machine Learning
Once we finished with data transformation and visualization, we can define the final data frame before machine learning application. To end this, we are going to select only two columns for features and one label column which will be flower type.
var derivedDF = df["SepalArea","PetalArea","flower_type"];
derivedDF.Head(5)
Since we are going to use ML.NET, we need to declare Iris in order to load the data into ML.NET.
class Iris
{
public float PetalArea { get; set; }
public float SepalArea { get; set; }
public string Species { get; set; }
}
MLContext mlContext = new MLContext(seed:2019);
Then load the data from Daany data frame into ML.NET:
IDataView dataView = mlContext.Data.LoadFromEnumerable<Iris>
(derivedDF.GetEnumerator<Iris>((oRow) =>
{
var prRow = new Iris();
prRow.SepalArea = Convert.ToSingle(oRow["SepalArea"]);
prRow.PetalArea = Convert.ToSingle(oRow["PetalArea"]);
prRow.Species = Convert.ToString(oRow["flower_type"]);
return prRow;
}));
Once we have data, we can split it into train and test sets:
var trainTestData = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2);
var trainData = trainTestData.TrainSet;
var testData = trainTestData.TestSet;
The next step in prepare the data for training is define pipeline for dtaa transformation and feature engineering:
IEstimator<ITransformer> dataPipeline =
mlContext.Transforms.Conversion.MapValueToKey
(outputColumnName: "Label", inputColumnName: nameof(Iris.Species))
.Append(mlContext.Transforms.Concatenate
("Features",nameof(Iris.SepalArea), nameof(Iris.PetalArea)));
Once we complete the preparation part, we can perform the training part. The training start by calling Fit to the pipeline:
%%time
IEstimator<ITransformer> lightGbm = mlContext.MulticlassClassification.Trainers.LightGbm();
TransformerChain<ITransformer> model = dataPipeline.Append(lightGbm).Fit(trainData);
Once the training is completes, we have trained model which can be evaluated. In order to print the evaluation result with formatting, we are going to install Daany DataFrame extension which has implementation of printing results:
var predictions = model.Transform(trainData);
var metricsTrain = mlContext.MulticlassClassification.Evaluate(predictions);
ConsoleHelper.PrintMultiClassClassificationMetrics("TRAIN Iris DataSet", metricsTrain);
ConsoleHelper.ConsoleWriteHeader("Train Iris DataSet Confusion Matrix ");
ConsoleHelper.ConsolePrintConfusionMatrix(metricsTrain.ConfusionMatrix);
var testPrediction = model.Transform(testData);
var metricsTest = mlContext.MulticlassClassification.Evaluate(testPrediction);
ConsoleHelper.PrintMultiClassClassificationMetrics("TEST Iris Dataset", metricsTest);
ConsoleHelper.ConsoleWriteHeader("Test Iris DataSet Confusion Matrix ");
ConsoleHelper.ConsolePrintConfusionMatrix(metricsTest.ConfusionMatrix);
As can be seen, we have a 100% accurate model for Iris flower recognition. Now, let’s add a new column into the data frame called Prediction to have a model prediction in the data frame.
In order to do that, we are evaluating the model on the train and the test data set. Once we have a prediction for both sets, we can join them and add as a separate column in Daany data frame. The following code does exactly what we described previously.
var flowerLabels = DataFrameExt.GetLabels(predictions.Schema).ToList();
var p1 = predictions.GetColumn<uint>("PredictedLabel").Select(x=>(int)x).ToList();
var p2 = testPrediction.GetColumn<uint>("PredictedLabel").Select(x => (int)x).ToList();
p1.AddRange(p2);
var p = p1.Select(x => (object)flowerLabels[x-1]).ToList();
var dic = new Dictionary<string, List<object>> { { "PredictedLabel", p } };
var dff = derivedDF.AddColumns(dic);
dff.Head()
The output above shows the first few rows in the data frame. To see the few last rows from the data frame, we call a Tail method.
dff.Tail()
In this blog post, we saw how we can be more productive when using .NET Jupyter Notebook with Machine Learning and Data Exploration and transformation, by using ML.NET and Daany – DAtaANalYtics library. The complete source code for this notebook can be found at GitHub repo: https://github.com/bhrnjica/notebooks/blob/master/net_jupyter_notebook_part2.ipynb
Bahrudin Hrnjica holds a Ph.D. degree in Technical Science/Engineering from University in Bihać.
Besides teaching at University, he is in the software industry for more than two decades, focusing on development technologies e.g. .NET, Visual Studio, Desktop/Web/Cloud solutions.
He works on the development and application of different ML algorithms. In the development of ML-oriented solutions and modeling, he has more than 10 years of experience. His field of interest is also the development of predictive models with the ML.NET and Keras, but also actively develop two ML-based .NET open source projects: GPdotNET-genetic programming tool and ANNdotNET - deep learning tool on .NET platform. He works in multidisciplinary teams with the mission of optimizing and selecting the ML algorithms to build ML models.
He is the author of several books, and many online articles, writes a blog at http://bhrnjica.net, regularly holds lectures at local and regional conferences, User groups and Code Camp gatherings, and is also the founder of the Bihac Developer Meetup Group. Microsoft recognizes his work and awarded him with the prestigious Microsoft MVP title for the first time in 2011, which he still holds today.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 This kind of Notebook is excellent for classroom examples, homeworks, CodeProject articles, and many other purposes.
This kind of Notebook is excellent for classroom examples, homeworks, CodeProject articles, and many other purposes.