Here we will create a simple container image to use for experimentation and training with the Intel/AMD CPU.
Introduction
Container technologies, such as Docker, significantly simplify dependency management and portability of your software. In this series of articles, we explore Docker usage in Machine Learning (ML) scenarios.
This series assumes that you are familiar with ML, containerization in general, and Docker in particular. You are welcome to download the project code.
In the previous article in the series, we have discussed Docker basics. In this article, we’ll start applying this knowledge while creating and running containers in the various ML scenarios. First, we’ll create a generic container for experimentation and training.
Base Image
When considering image size and security, Alpine Linux could seem to be an obvious choice for a base image. For Python applications, it is not so simple though. Alpine uses musl – a C library that is different from glib, which most standard Linux distributions use. This renders most compiled Pip wheels incompatible, so a compilation is required during installation. In effect, setting up any non-trivial Python environment (with multi-level dependencies) takes much more time on Alpine than on a more popular distribution such as Debian or Ubuntu. Not only this, but the resulting image may be larger, and the code may work slower!
For more details, have a look at this article. To avoid the above issues, we’ll choose a minimal version of the official Python image built on top of Debian 10 (Buster) as the base: python:3.8.8-slim-buster.
Creating Dockerfile
We need an image with basic ML libraries and Jupyter Notebooks to handle experimentation. We’ll store all the required libraries in the app/requirements.txt file:
numpy==1.19.5
pandas==1.2.2
scikit-learn==0.24.1
matplotlib==3.3.4
jupyter==1.0.0
opencv-python==4.5.1.48
tensorflow-cpu==2.4.0
Now, let’s start creating our Dockerfile:
FROM python:3.8.8-slim-buster
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update \
&& apt-get -y install --no-install-recommends ffmpeg libsm6 libxext6 \
&& apt-get autoremove -y && apt-get clean -y && rm -rf /var/lib/apt/lists/*
First, after switching to the non-interactive mode, we install all system dependencies required by our Python libraries, and clean afterwards to limit the image size. Note that these dependencies may vary if you change requirements.txt.
Next, we use a non-root user when running a container:
ARG USERNAME=mluser
ARG USERID=1000
RUN useradd --system --create-home --shell /bin/bash --uid $USERID $USERNAME
Using arguments for the USERNAME and USERID values will let us replace them during build and execution if required.
Then, let’s configure a Python environment:
COPY app/requirements.txt /tmp/requirements.txt
RUN pip3 install --no-cache-dir -r /tmp/requirements.txt \
&& rm /tmp/requirements.txt
Finally, we switch to the new user and start a Jupyter Notebook by default if no other command is specified:
USER $USERNAME
WORKDIR /home/$USERNAME/app
EXPOSE 9000
CMD ["jupyter", "notebook", "--ip", "0.0.0.0", "--port", "9000"]
Building Image
On Linux, we should always use a predetermined user to run a container. This ensures that container’s internal processes, as well as the files saved to a mapped host drive, will have an expected owner. In the following example, we ensure that the current user has proper permissions to all files created when building image mld02_cpu_experiment:
$ docker build --build-arg USERID=$(id -u) -t mld02_cpu_experiment .
The provided --build-arg USERID parameter will replace Dockerfile’s predefined USERID argument with the provided value.
In practice, you would need this only when you run the container locally on Linux. The default value from the image (1000) can cause trouble on the host, and the container needs write permissions to user folders or files included in the image. In any other case, you can skip this step.
Running Container
After the container is built, we can try it out. Assuming we have downloaded and extracted the sample code, we run our Jupyter Notebook instance:
$ docker run -p 9000:9000 -v $(pwd)/app:/home/mluser/app -v $(pwd)/data:/home/mluser/data --rm --user $(id -u):$(id -g) mld02_cpu_experiment
On Windows:
$ docker run -p 9000:9000 -v %cd%/app:/home/mluser/app -v %cd%/data:/home/mluser/data --rm mld02_cpu_experiment
The arguments here are: -p to map the container port to the host port, -v to map host’s app and data folders to the container folders (absolute paths), and --user to ensure we execute the container code in the context of current host’s user (to have a correct owner for the files in the mapped folder). The --rm flag ensures that all container data will be automatically removed as soon as the container is stopped.
If everything goes well, we should see logs of our Jupyter Notebook spinning up:
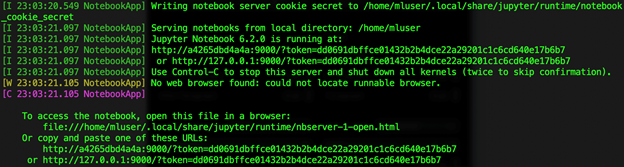
Thanks to the mapped ports, we should be able to open the notebook in a web browser using http://localhost:9000 (or the URL from the above log).

The Simple Training.ipynb contains everything we need to train our sample MNIST model using a simple TensorFlow model. After executing all of its cells, we should expect the following confirmation that the model's predictions are correct:
We will use the trained model saved by this notebook for inference in the following articles.
Summary
In this article, we’ve created a basic container for experimentation. In the next one, we’ll create a container to run a CPU inference on the trained model.
Jarek has two decades of professional experience in software architecture and development, machine learning, business and system analysis, logistics, and business process optimization.
He is passionate about creating software solutions with complex logic, especially with the application of AI.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




