Here we explain how to continuously integrate model changes and continuously train our model when new data was gathered.
In this series of articles, we’ll walk you through the process of applying CI/CD to the AI tasks. You’ll end up with a functional pipeline that meets the requirements of level 2 in the Google MLOps Maturity Model. We’re assuming that you have some familiarity with Python, Deep Learning, Docker, DevOps, and Flask.
In the previous article, we discussed the model creation, auto-adjustment and notifications of our CI/CD MLOps Pipeline. In this one, we’ll look at the code required to implement Continuous Training in our ML pipeline. The diagram below shows where we are in our project process.
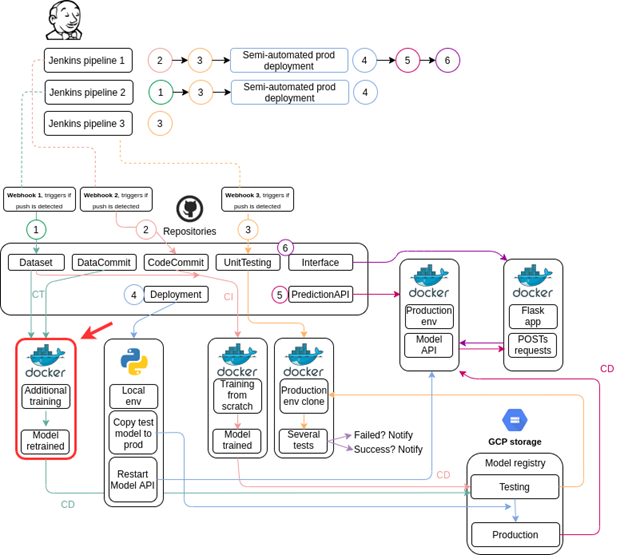
Keep in mind that this workflow will be executed whenever there’s a push to the Dataset repository. The script will check if there’s a model available in the production or testing registry. It will then retrain the model it finds. This is our app files structure:

We show the code files in a condensed version. For the full version, see the code repository.
data_utils.py
The data_utils.py code does exactly the same as before. It loads the data from the repository, transforms it, and saves the resulting model to GCS. The only difference is that now this file contains two additional functions. One of them checks if a model exists in the testing registry, and the other one loads that model.
Take the data_utils.py file from the previous article and add these functions to the end of the file:
def previous_model(bucket_name,model_type,model_filename):
try:
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
status = storage.Blob(bucket = bucket, name = '{}/{}'.format(model_type,model_filename)).exists(storage_client)
return status,None
except Exception as e:
print('Something went wrong when trying to check if previous model exists GCS bucket. Exception: ',flush=True)
return None,e
def load_model(bucket_name,model_type,model_filename):
try:
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob1 = bucket.blob('{}/{}'.format(model_type,model_filename))
blob1.download_to_filename('/root/'+str(model_filename))
return True,None
except Exception as e:
print('Something went wrong when trying to load previous model from GCS bucket. Exception: '+str(e),flush=True)
return False,e
email_notifications.py
The email_notifications.py code is essentially the same as before, except it now sends different messages.
import smtplib
import os
sender = ‘example@gmail.com’
receiver = ['svirahonda@gmail.com']
smtp_provider = 'smtp.gmail.com'
smtp_port = 587
smtp_account = ‘example@gmail.com’
smtp_password = ‘your_password’
def training_result(result,accuracy):
if result == 'old_evaluation_prod':
message = "A data push has been detected. Old model from production has reached more than 0.85 of accuracy. There's no need to retrain it."
if result == 'retrain_prod':
message = 'A data push has been detected. Old model from production has been retrained and has reached more than 0.85 of accuracy. It has been saved into /testing.'
if result == 'old_evaluation_test':
message = "A data push has been detected,. Old model from /testing has reached more than 0.85 of accuracy. There's no need to retrain it."
if result == 'retrain_test':
message = 'A data push has been detected. Old model from /testing has been retrained and reached more than 0.85 of accuracy. It has been saved into /testing.'
if result == 'poor_metrics':
message = 'A data push has been detected. Old models from /production and /testing have been retrained but none of them reached more than 0.85 of accuracy.’
if result == 'not_found':
message = 'No previous models were found at GCS. '
message = 'Subject: {}\n\n{}'.format('An automatic training job has ended recently', message)
try:
server = smtplib.SMTP(smtp_provider,smtp_port)
server.starttls()
server.login(smtp_account,smtp_password)
server.sendmail(sender, receiver, message)
return
except Exception as e:
print('Something went wrong. Unable to send email: 'str(e),flush=True)
return
def exception(e_message):
try:
message = 'Subject: {}\n\n{}'.format('An automatic training job has failed recently', e_message)
server = smtplib.SMTP(smtp_provider,smtp_port)
server.starttls()
server.login(smtp_account,smtp_password)
server.sendmail(sender, receiver, message)
return
except Exception as e:
print('Something went wrong. Unable to send email.',flush=True)
print('Exception: ',e)
return
task.py
The task.py code orchestrates execution of the above files. Same as before, it checks if GPUs exist on the host machine, initializes GPUs (if any are found), handles the arguments passed to the code execution, and loads the data. and start retraining. Once retraining ends, the code will push the resulting model to the testing registry and notify the product owner. Let’s see what the code looks like:
import tensorflow as tf
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import load_model
import argparse
import data_utils
import data_utils, email_notifications
import sys
import os
from google.cloud import storage
import datetime
model_name = 'best_model.hdf5'
def initialize_gpu():
if len(tf.config.experimental.list_physical_devices('GPU')) > 0:
tf.config.set_soft_device_placement(True)
tf.debugging.set_log_device_placement(True)
return
def start_training(args):
X_train, X_test, y_train, y_test = data_utils.load_data(args)
initialize_gpu()
model_gcs_prod = data_utils.previous_model(args.bucket_name,'production',model_name)
model_gcs_test = data_utils.previous_model(args.bucket_name,'testing',model_name)
if model_gcs_prod[0] == True:
train_prod_model(X_train, X_test, y_train, y_test,args)
if model_gcs_prod[0] == False:
if model_gcs_test[0] == True:
train_test_model(X_train, X_test, y_train, y_test,args)
if model_gcs_test[0] == False:
email_notifications.training_result('not_found',' ')
sys.exit(1)
if model_gcs_test[0] == None:
email_notifications.exception('Something went wrong when trying to check if old testing model exists. Exception: '+model_gcs_test[1]+'. Aborting automatic training.')
sys.exit(1)
if model_gcs_prod[0] == None:
email_notifications.exception('Something went wrong when trying to check if old production model exists. Exception: '+model_gcs_prod[1]+'. Aborting automatic training.')
sys.exit(1)
def train_prod_model(X_train, X_test, y_train, y_test,args):
model_gcs_prod = data_utils.load_model(args.bucket_name,'production',model_name)
if model_gcs_prod[0] == True:
try:
cnn = load_model(model_name)
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
saved_ok = data_utils.save_model(args.bucket_name,model_name)
if saved_ok[0] == True:
email_notifications.training_result('old_evaluation_prod', model_acc)
sys.exit(0)
else:
email_notifications.exception(saved_ok[1])
sys.exit(1)
else:
cnn = load_model(model_name)
checkpoint = ModelCheckpoint(model_name, monitor='val_loss', verbose=1, save_best_only=True, mode='auto', save_freq="epoch")
cnn.fit(X_train, y_train, epochs=args.epochs,validation_data=(X_test, y_test), callbacks=[checkpoint])
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
saved_ok = data_utils.save_model(args.bucket_name,model_name)
if saved_ok[0] == True:
email_notifications.training_result('retrain_prod',model_acc)
sys.exit(0)
else:
email_notifications.exception(saved_ok[1])
sys.exit(1)
else:
return
except Exception as e:
email_notifications.exception('Something went wrong when trying to retrain old production model. Exception: '+str(e))
sys.exit(1)
else:
email_notifications.exception('Something went wrong when trying to load old production model. Exception: '+str(model_gcs_prod[1]))
sys.exit(1)
def train_test_model(X_train, X_test, y_train, y_test,args):
model_gcs_test = data_utils.load_model(args.bucket_name,'testing',model_name)
if model_gcs_test[0] == True:
try:
cnn = load_model(model_name)
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
email_notifications.training_result('old_evaluation_test',model_acc)
sys.exit(0)
else:
cnn = load_model(model_name)
checkpoint = ModelCheckpoint(model_name, monitor='val_loss', verbose=1, save_best_only=True, mode='auto', save_freq="epoch")
cnn.fit(X_train, y_train, epochs=args.epochs, validation_data=(X_test, y_test), callbacks=[checkpoint])
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
saved_ok = data_utils.save_model(args.bucket_name,model_name)
if saved_ok[0] == True:
email_notifications.training_result('retrain_test',model_acc)
sys.exit(0)
else:
email_notifications.exception(saved_ok[1])
sys.exit(1)
else:
email_notifications.training_result('poor_metrics',model_acc)
sys.exit(1)
except Exception as e:
email_notifications.exception('Something went wrong when trying to retrain old testing model. Exception: '+str(e))
sys.exit(1)
else:
email_notifications.exception('Something went wrong when trying to load old testing model. Exception: '+str(model_gcs_test[1]))
sys.exit(1)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--bucket-name', type=str, default = 'automatictrainingcicd-aiplatform',help='GCP bucket name')
parser.add_argument('--epochs', type=int, default=2, help='Epochs number')
args = parser.parse_args()
return args
def main():
args = get_args()
start_training(args)
if __name__ == '__main__':
main()
Dockerfile
The Dockerfile handles the Docker container build. It loads the dataset from its repository, loads the code files from their repository, and defines where the container execution should start:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-0
WORKDIR /root
RUN pip install pandas numpy google-cloud-storage scikit-learn opencv-python
RUN apt-get update; apt-get install git -y; apt-get install -y libgl1-mesa-dev
ADD "https://www.random.org/cgi-bin/randbyte?nbytes=10&format=h" skipcache
RUN git clone https:
ADD "https://www.random.org/cgi-bin/randbyte?nbytes=10&format=h" skipcache
RUN git clone https:
RUN mv /root/AutomaticTraining-DataCommit/task.py /root
RUN mv /root/AutomaticTraining-DataCommit/data_utils.py /root
RUN mv /root/AutomaticTraining-DataCommit/email_notifications.py /root
ENTRYPOINT ["python","task.py"]
You’ll notice the ADD instructions in the code. These force the build process to always pull the repository content – rather than cashing them in the local registry – when building the container.
Once you’ve built and ran the container locally, you should be able to retrain your models with newly gathered data. We haven’t talked about triggering this job yet. We’ll cover this step later, when discussing GitHub webhooks and Jenkins, but essentially Jenkins will be able to trigger this workflow whenever a push is detected in the corresponding repository. The push is detected via a Webhook, a method configured in the repository itself.
At the end of the process, you should find the model file stored in the GCS testing registry.
Next Steps
In the next article, we’ll develop a model unit testing container. Stay tuned!
Sergio Virahonda grew up in Venezuela where obtained a bachelor's degree in Telecommunications Engineering. He moved abroad 4 years ago and since then has been focused on building meaningful data science career. He's currently living in Argentina writing code as a freelance developer.





