|
That's great news! CodeProject.AI Server 2.0.5 introduces runtime module installation/uninstallation, a new Module Repository, and notable modules like Object Detection YOLOv5 3.1, ALPR, and Optical Character Recognition. The .NET-based Object Detection module has seen a 20% increase in detection speeds using ML.NET. This version is a solid foundation for AI functionality. Download it today for AIenthusiasts<ahref="https://calcularrfc.com.mx/"></a>. - Sean Ewington, CodeProject.
|
|
|
|
|

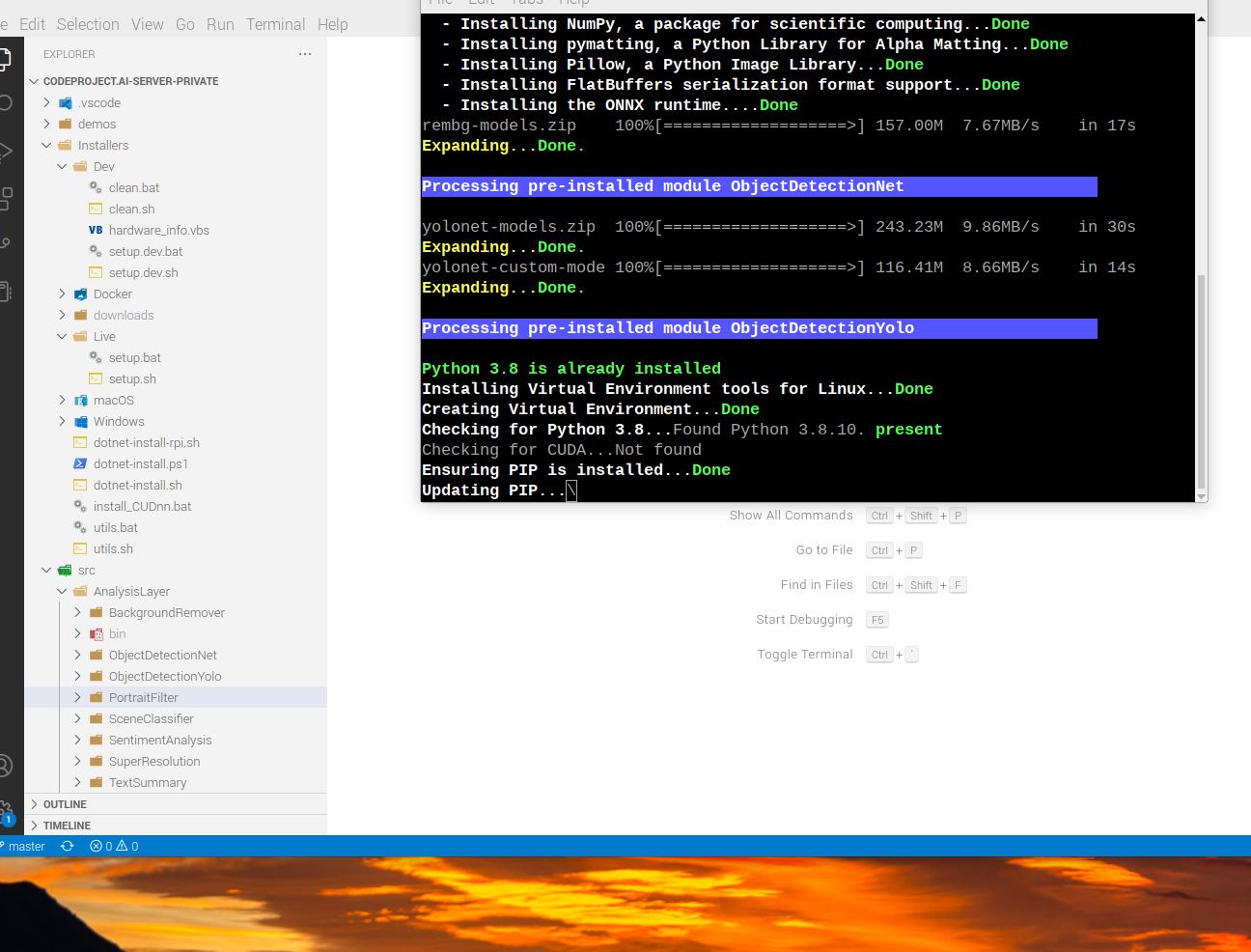
Tweaking the install / setup scripts on a Raspberry Pi by running VS Code and our installers on the Raspberry Pi natively. Same experience as a Mac or Windows box. Same tools, same scripts, same models. All in a teeny tiny little not-so-toy computer.
cheers
Chris Maunder
|
|
|
|
|
The ‘server’ part of CodeProject.AI Server is now .NET 7, with all the wonderful teething problems and workarounds that make a developer’s life so much fun.
While our server is only a very small part of the overall system, it’s crucial that it’s fast, easy to debug, and runs everywhere we need it to. With .NET 7 there are a bunch of performance improvements and some new features that will benefit us in the future. .NET 6 will be a distant memory for everyone soon enough so we’ve gone through the upgrade pain now to save us later on.
The upgrade raised several errors and warnings about null references or using nulls inappropriately, due in part to additional features in C# and .NET 7. A few easy fixes later and ... the application didn't run properly.
It turns out there's a bug in .NET 7.0.0 where loading a dictionary from a configuration file fails. More specifically, option binding for a ConcurrentDictionary works fine in .NET 6, but fails in .NET 7. I have a workaround which I’ve posted on CodeProject here: Workaround for ServiceCollection.Configure<t> failing where T is ConcurrentDictionary<string, tmyconfig=""> in NET7. This issue will be resolved in .NET 7.0.1.
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|

Some Blue Iris users who are using CodeProject.AI Server want to know how to detect objects at night. Or some Blue Iris users are able to detect objects at night, but the detection is unreliable. In one case a user from the ipcamtalk forum experienced issues detecting cars at night. The user finds if the car drives fast enough, CodeProject.AI Server can detect it, if the car drives too slow, CodeProject.AI Server only scans the headlights.
The user tried changing their Artificial Intelligence settings to check live images at various intervals: 100 ms, 200 ms, 500 ms, and 750 ms, but to no avail. However, the issue is not in the intervals of checking the live images, but instead the number of real-time images to analyze.
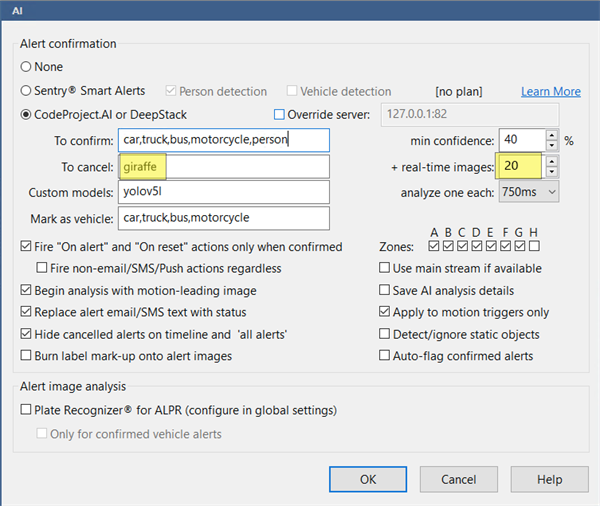
Under the setting +real-time images, simply increase this number until detection is no longer a problem, and in the To cancel box, put an item like giraffe or banana. This will stop Blue Iris sending CodeProject.AI Server images as soon as it finds something in the To confirm box. The To cancel box forces Blue Iris to send CodeProject.AI Server every image.
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
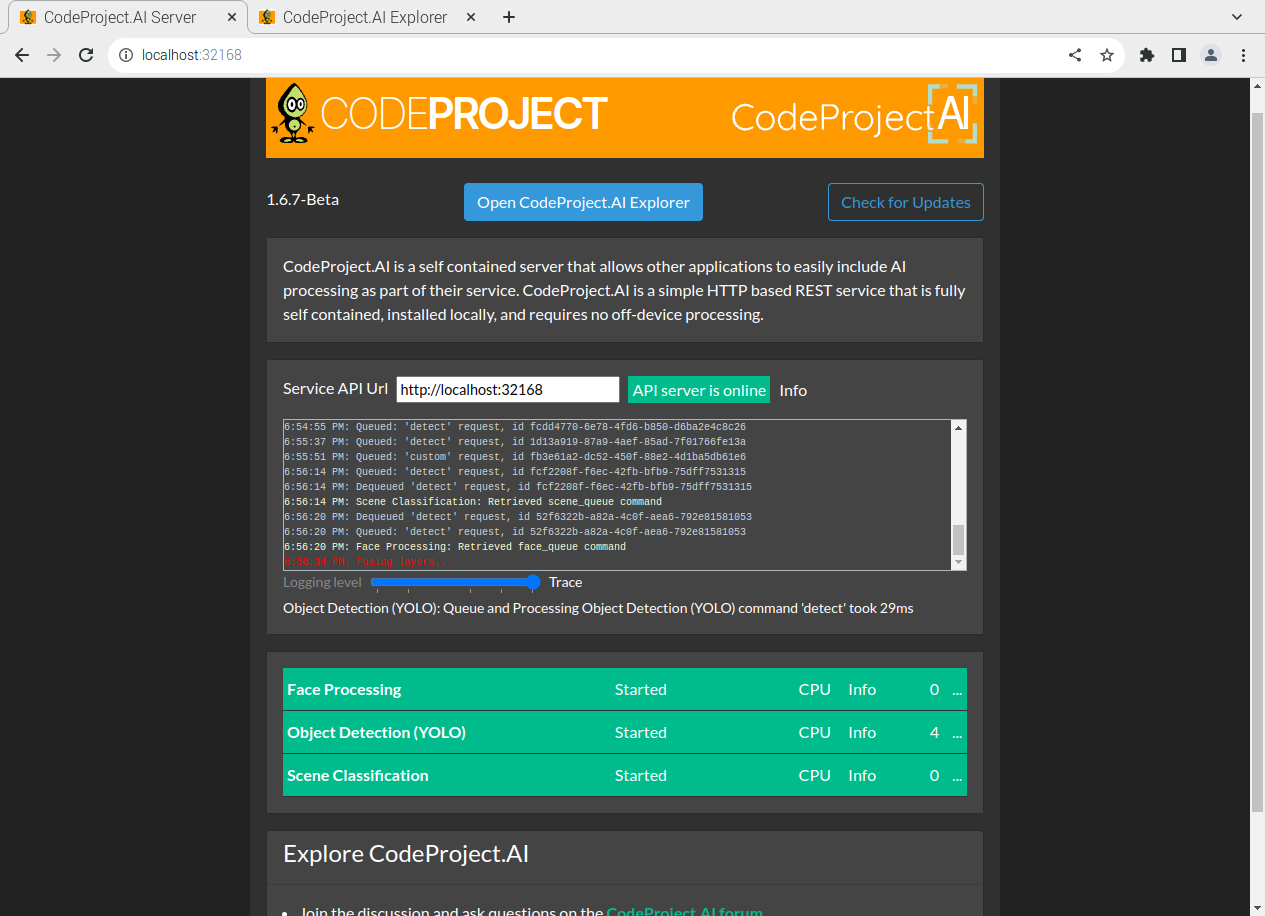
We've hit 50,000 downloads of CodeProject.AI Server!
Thank you to everyone who downloaded CodeProject.AI Server, and an extra special thank you to those that tried it, are using it, have posted bugs, suggestions, encouragements, ideas and wisdom. Most of all, thanks for giving it a go and supporting us in this crazy fun journey.
CodeProject.AI Server has come a long way since its release in January of this year. We've added support for custom models, GPU support including integrated GPUs and the Apple Silicon M chips, and we’re adding more Docker containers including our latest which support Arm64 on Apple and Raspberry Pi devices. We’re also proud to be the AI service of choice for Blue Iris. And with the improved integration with Blue Iris, we’re now running live for tens of thousands of Blue Iris users.
And this is just the beginning. We're committed to making our fast, free, self-hosted, AI server as easy to use as possible, everywhere you need to use it.
If you're interested in learning, or getting involved in AI, download CodeProject.AI Server today.
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
A number of people are using CodeProject.AI Server with Blue Iris, a video security software package. Our server supplies the AI smarts to detect things like vehicles, people, and custom objects from the video feeds.
Last month we got an error from a Blue Iris user who was using GPU processing. The error Blue Iris gave them was "AI: not responding."
In their error report, the user indicated they were using an NVIDIA GeForce GTX 1070 Ti which, we discovered, is not able to use half precision in its image processing for AI.
When doing a prediction (or inference) of an image to determine what's in it, this prediction process uses a model. Within the model there is a set of weights that are basically the coefficients that are assigned to various points in the model. When you download a model, you are downloading (among other things) a series of weights that have been trained for a particular process or AI task such as detecting raccoons. The weights assist in considering the input, like an image, to help determine the values of a set of outputs, one of which could be whether a raccoon was detected in the image.
This training process uses a set of inputs with known outputs. It runs the detection process and measures the error of the output to the expected known output. The training process tries to minimize the error by backwards propagating and adjusting all the weights all the way back, then doing it over and over again until it converges to an acceptable error rate. This process takes a lot of time and processing power.
The detection process uses the trained model’s weights to take an input - in this case an image - and calculates the probability that an object was trained to detect is in the image, and where it is located.
Part of this processing time has to do with your graphics card. Some graphics cards use half precision floating-point format, or FP16. If the card does not support half precision, or the processing is being done on the CPU, 32-bit floating point (FP32) is used. These are the number formats that are used in image processing.
For image processing, FP16 is preferred. Newer NVIDIA GPUs have specialized cores called Tensor Cores which can process FP16.
But for those with graphics cards that do not have Tensor Cores and are trying to use Blue Iris with CodeProject.AI Server, they would get an error message that read "AI: not responding."
In order to address this, we determined which models of the NVIDIA GPUs actually supported FP16 and created a table which says, "these graphics cards don't support FP16 and so don't try and use FP16 for those GPUs anymore." Hopefully we've got a comprehensive list. We may not and we'll have to adjust it if we find any more, but for now, here is our list:
- TU102
- TU104
- TU106
- TU116
- TU117
- GeoForce GT 1030
- GeForce GTX 1050
- GeForce GTX 1060
- GeForce GTX 1060
- GeForce GTX 1070
- GeForce GTX 1080
- GeForce RTX 2060
- GeForce RTX 2070
- GeForce RTX 2080
- GeForce GTX 1650
- GeForce GTX 1660
- MX550
- MX450
- Quadro RTX 8000
- Quadro RTX 6000
- Quadro RTX 5000
- Quadro RTX 4000
- Quadro P620
- Quadro P400
- T1000
- T600
- T400
- T1200
- T500
- T2000
- Tesla T4
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|

Way, way more fiddly than I expected but there you have it.
Here are the quick notes on this:
- The Raspberry Pi 400 is a self contained quad core 64bit Arm-based Raspberry Pi built into a keyboard.

It comes preinstalled with a 32bit OS. Sigh. Download the imager from Raspberrypi.com and make yourself a 64bit OS installer. It's easy, just annoying.
- Building a docker container for Arm is easy, sort of. Once you have the correct base image, you have the build targets correct, you get things to build and then the image builds properly, then it's all smooth sailing. We settled with using arm64v8/ubuntu:22.04 as the base Docker image. I built using an M1 mac mini because the thing is so crazy fast for such a seemingly modest machine.
- Fitting everything into a Docker image that will fit on a Pi means making hard calls. For this demo I only included the Python Face detector, Object detector and scene classifier. This made it almost pocket sized at 1.5Gb. Build, push, move back to Pi...
- Back to the Raspberry Pi, you'll note Raspberry Pi's don't come with Docker. Update your system and install Docker:
sudo apt update
sudo apt upgrade
curl -fsSL <a href="https://get.docker.com">https://get.docker.com</a> -o get-docker.sh
sudo bash get-docker.sh
- Pull the RaspberryPi image:
sudo docker pull codeproject/ai-server:rpi64-1.6.8.0
- Run the Docker image:
docker run -p 32168:32168 --name CodeProject.AI-Server -d codeproject/ai-server:rpi64-1.6.8.0
- Launch the dashboard: http://localhost:32168
Memory is a huge issue and this docker image is not exactly useable at this point. What you're seeing here is literally the first run - a proof of concept that it all works give or take resource constraints. The servers are up, the queues are being polled, the logs are being written, the model layers are being fused.
Small steps, but another small hill climbed. Onto the next.
cheers
Chris Maunder
|
|
|
|
|
Recently for CodeProject.AI Server we were looking to increase the number of frames per second we can handle (throughput) as well as figure out how to be able to analyze frames from a video stream on the backend.
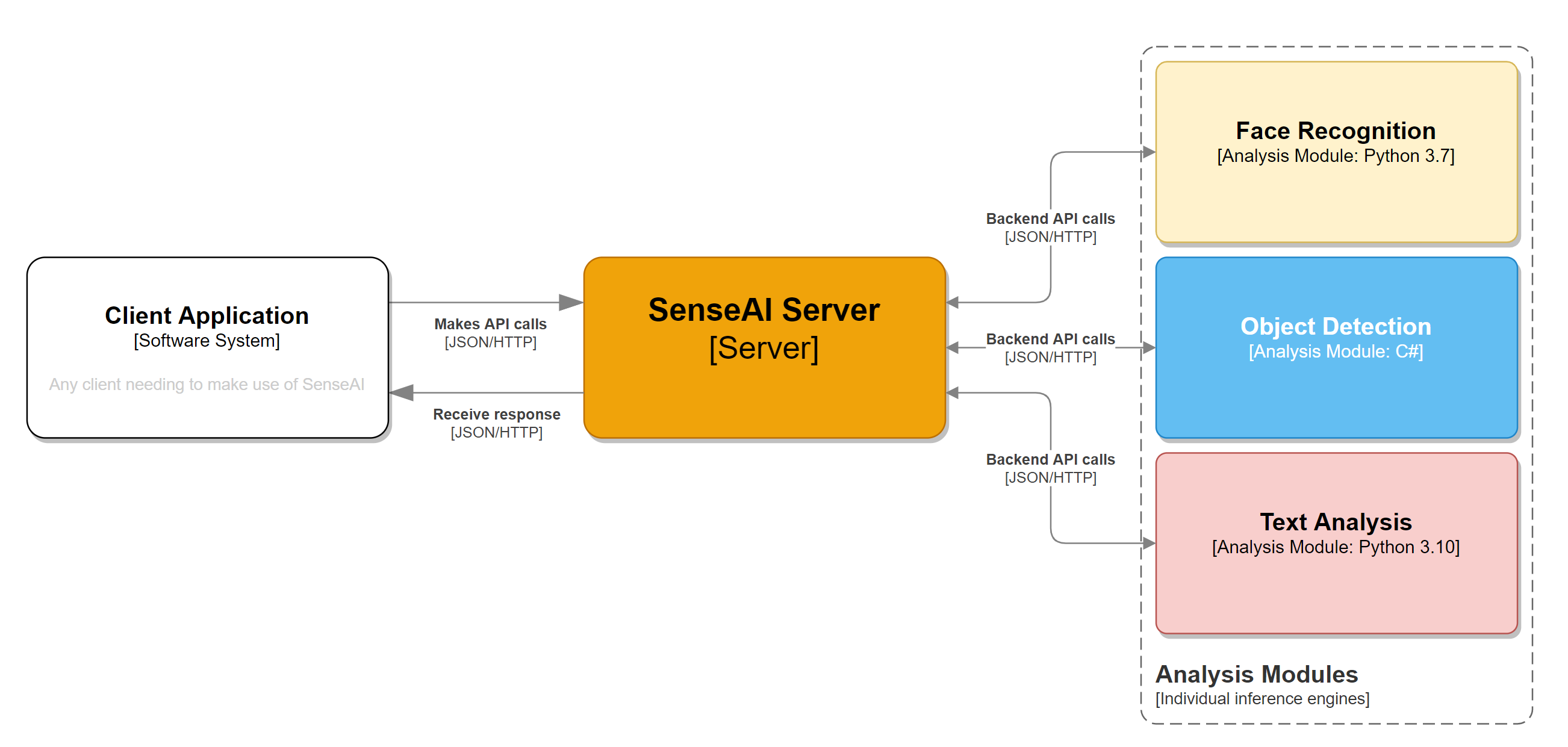
Here's the flow of how CodeProject.AI Server works. Someone writes an application that calls CodeProject.AI Server with a request for data that gets put into a queue for the backend module. The backend module requests data from the queue, gets it, figures out what it supposed to do with it, processes it, and then it sends the response back, which gets sent back to the original caller.
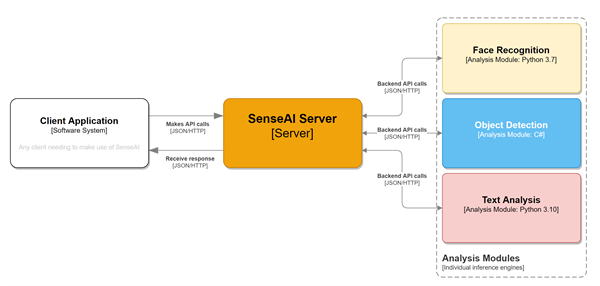
See Adding new modules to CodeProject.AI - CodeProject.AI Server v1.6.5 for more details on the system architecture.
So, what we're doing is looking at the part between the frontend and the backend module, trying to reduce the communication time there.
To help do this we looked at SignalR, Microsoft's library which can establish a permanent or semi-permanent connection. The nice thing about SignalR is that it's got all the infrastructure built in for handling reconnects, doing remote procedure calls, and streaming data.
We hunted around for an existing Python package to handle SignalR for Python using asynchronous calls. Unfortunately, there wasn't much. There was one Python package, signalr-async, that looked promising, but it required Python 3.8 or higher. Currently CodeProject.AI Server is running Python 3.8 for Linux, and Python 3.7 for Windows for some modules.
Ultimately, we ended up pulling the code from that Python package and getting it to work on Python 3.7 and 3.8.
We had some trouble getting it to work properly, so we wrote a little .NET client (because it's easier to debug and understand), which helped us realize we were using the Python package incorrectly.
In our Python code, we're running multiple tasks. And it turns out that each of those tasks needed a separate SignalR connection, as opposed to sharing that connection across all the tasks.
Once we made that change things were working, but it was slower than the existing http request/response method we currently use.
So, we went back to the aiohttp Python package documentation. It turns out we’re already doing the best we can in terms of communication speed between the frontend and the backend module. This is because the session object maintains a pool of connections for reuse, eliminating most of the overhead of making a request.
But that's how it goes. Not all experiments are successful, but the result is important. It tells us where our limits are and helps us move on to doing things better and faster.
We're still going to be looking at getting streaming working in the most efficient manner so we can process video streams at a higher rate. It appears aiohttp can handle streams in addition to standard request/response communication, but more on that later.
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|
I know your using SignalR as per the article, but did you ever consider looking into using the "WAMP" protocol?
The Web Application Messaging Protocol — Web Application Messaging Protocol version 2 documentation
I've been using it for a number of years now for everything from web messaging, to replacing all those horrible Grpc calls from proto-buf.
There's a really great implementation of it in C#, in the form of "Wamp Sharp"
WampSharp
and if you look at the protocol page in the first link there are top class frameworks for all the mainstream languages, including python (See the implementations page on the first site link)
|
|
|
|
|
Last week was Docker week.
Last week was meant to be, "Let's completely revamp the installer in preparation for new modules," but we're all software developers so we know how that goes.
Some back story:
CodeProject.AI Server is, well, a server. It's deployed as a standalone service, doesn't need a built-in UI, and is perfect for Docker. Especially since those who employ CodeProject.AI Server will often have other services in other Docker containers alongside.
For those new to Docker, Docker is a system that allows you to create an entire system - OS, applications, data, the lot - inside a single container. That container can then be run anywhere Docker runs, which is almost everywhere. So I build a Docker container that has Ubuntu installed as the base OS, add CodeProject.AI Server, the analysis modules, the AI models, and drivers if needed, and then I can run that Docker image on my PC, my Mac, my Raspberry Pi, or my QNAP storage device. One container, any platform.
Tip 1. It's important to note that when running Docker, performance depends on the difference between the OS and architecture in the container and the OS and architecture of the system upon which you run that container. This is called foreshadowing.
We want our CodeProject.AI system to be able to add and update modules at runtime. That's not too hard. But we need it to be fast and efficient. We also need it to work on the hardware many users will have. And we want to use the tools we know and love.
Tip 2: Tools for cross platform development will work perfectly well for most, but not all, environments. This is also foreshadowing.
The first step in improving the installer is that we need to ensure CodeProject.AI Server runs in Docker nicely. CPU only is perfect on Intel Mac, Linux and Windows. Our Nvidia GPU Docker image works on Windows and Linux perfectly (macOS doesn't support Nvidia anymore. It's a long sordid story...). M1 / M2 macOS... doesn't work.
Tip 3: When building cross-platform solutions with cross-platform aware tools and compilers you generally shouldn't need to worry about the hardware and OS architectures you're targeting. The tools should be self-aware enough to handle that for you. Yeah, foreshadowing.
So we want to
- allow CodeProject.AI Server to be updateable at runtime
- ...and to do this while running in a Docker container
- ...on any platform
- ...using the tools generally availble to developers
Which means
- Our code should work with Visual Studio Code and VS 2022
- ... in Linux, macOS, and Windows, both x64 and Arm64
- ... and be able to generate Docker images that work on these platforms
- ... and allow updates and installs to happen at runtime.
See how the goal of the week has been pushed to the bottom?
Long story short is that we hit these issues:
- VSCode works really well cross platform, except when it comes to Intel macOS vs Apple Silicon macOS. You have to do some workarounds
Your tasks.json file, for instance, allows you to apply conditionals based on whether you're in Windows, Linux or OSX. But OSX is now split between Intel and Apple Silicon. No real drama, but it means you can no longer have a one-task-fits-all solution. Break it up into Intel and M1 and make sure you choose the right one each time.
- Docker containers built using x64 OSs don't run efficiently on the Apple Silicon Arm64 (and we assume, any Arm64 OS like Raspberry Pi OS)
Again not a terrible hassle because there are Arm64 base Docker images for Ubuntu available. Instead of "from ubuntu:22.04" you do "from arm64v8/ubuntu:22.04" and your image will start off on the right footing.
- When you build for a given platform you need to include the correct libraries (eg Nuget) for your platform, and for this you need your compilers to get the correct information from their environment. For .NET this means ensuring the correct Runtime Identifier is specified in the project file.
This killed us. Some features simply aren't available on some platforms, or available as dev builds, so you need to specify different packages based on different OSs and hardware. You also need to ensure (in .NET) your RuntimeIdentifiers are correct so the package managers will hook up the correct builds of the packages.
What we did was include the following in each project file:
<PropertyGroup>
<IsWindows Condition="'$([System.Runtime.InteropServices.RuntimeInformation]::IsOSPlatform($([System.Runtime.InteropServices.OSPlatform]::Windows)))' == 'true'">true</IsWindows>
<IsLinux Condition="'$([System.Runtime.InteropServices.RuntimeInformation]::IsOSPlatform($([System.Runtime.InteropServices.OSPlatform]::Linux)))' == 'true'">true</IsLinux>
<IsOsx Condition="'$([System.Runtime.InteropServices.RuntimeInformation]::IsOSPlatform($([System.Runtime.InteropServices.OSPlatform]::OSX)))' == 'true'">true</IsOsx>
<IsArm64 Condition="'$([System.Runtime.InteropServices.RuntimeInformation]::OSArchitecture)' == 'Arm64'">true</IsArm64>
</PropertyGroup>
<PropertyGroup>
<RuntimeIdentifier Condition="'$(IsArm64)'!='true' And '$(IsWindows)'=='true'">win-x64</RuntimeIdentifier>
<RuntimeIdentifier Condition="'$(IsArm64)'=='true' And '$(IsWindows)'=='true'">win-arm64</RuntimeIdentifier>
<RuntimeIdentifier Condition="'$(IsArm64)'!='true' And '$(IsLinux)'=='true'">linux-x64</RuntimeIdentifier>
<RuntimeIdentifier Condition="'$(IsArm64)'=='true' And '$(IsLinux)'=='true'">linux-arm64</RuntimeIdentifier>
<RuntimeIdentifier Condition="'$(IsArm64)'!='true' And '$(IsOsx)'=='true'">osx-x64</RuntimeIdentifier>
<RuntimeIdentifier Condition="'$(IsArm64)'=='true' And '$(IsOsx)'=='true'">osx.12-arm64</RuntimeIdentifier>
</PropertyGroup>
<PropertyGroup>
<TargetFramework>net6.0</TargetFramework>
<TargetFramework Condition="'$(IsWindows)'!='true'">net6.0-windows</TargetFramework>
</PropertyGroup>
<Target Name="SettingsCheck" AfterTargets="BeforeBuild">
<Message Importance="High" Text="TargetFramework: $(TargetFramework)" />
</Target>
`
This gives us the platform (Windows, Linux or OSX, and the hardware (Arm64 or x64).
For the Microsoft.ML.OnnxRuntime package we know that it's compatible everywhere using the basic Microsoft.ML.OnnxRuntime. For general GPU support on Windows, use Microsoft.ML.OnnxRuntime.DirectML, and for CUDA GPU support (Windows and Linux) use Microsoft.ML.OnnxRuntime.Gpu. For Docker we're running Linux, x64, except for M1 chips where we use Linux, Arm64.
So to handle running our code natively as well as handling Docker builds, we get
<PackageReference Include="Microsoft.ML.OnnxRuntime.DirectML" Version="1.12.1" Condition="'$(IsWindows)'=='true'" />
<PackageReference Include="Microsoft.ML.OnnxRuntime.Gpu" Version="1.12.1" Condition="'$(IsLinux)'=='true' And '$(IsArm64)'!='true'" />
<PackageReference Include="Microsoft.ML.OnnxRuntime" Version="1.12.1" Condition="'$(IsLinux)'=='true' And '$(IsArm64)'=='true'" />
<PackageReference Include="Microsoft.ML.OnnxRuntime" Version="1.12.1" Condition="'$(IsOsx)'=='true'" />
We're not quite there yet for the M1 Docker image, but we're close. Once we have that done we can get back to starting our goal from 9AM last Monday morning.
cheers
Chris Maunder
modified 23-Oct-22 9:26am.
|
|
|
|
|
We’ve been working with Blue Iris to provide them the best AI support we can. Blue Iris is a video security and webcam software that does an amazing job of managing multiple cameras without overloading your system. It’s insanely full featured, and the addition of Object Detection using AI enables specific triggers in Blue Iris to be fired intelligently.
Last week Blue Iris included CodeProject.AI Server as part of its startup. Now when you install version Blue Iris 5 (versions 5.6.2.1 or higher) you will receive a popup that asks if you want to download and install CodeProject.AI Server, which will take you the CodeProject.AI Server download page.
To use CodeProject.AI Server with Blue Iris, simply install Blue Iris and CodeProject.AI Server, go to the AI tab in Blue Iris settings and check the box "Use AI server on IP/port." From here you can open the AI control panel which will load the CodeProject.AI Server console (which will also let you know if you're using the latest version or not).
Thanks,
Sean Ewington
CodeProject
modified 19-Oct-22 19:59pm.
|
|
|
|
|
Apple released their M series chips a few years ago, but it's only relatively recently that libraries such as PyTorch have provided support.
The benefits are dramatic. Some benchmarks show an over 20X increase in speed for the M1 GPU over just the CPU when running AI training and inference on an M1 Mac using the GPU vs the CPU.
So naturally I dug in and added M1/M2 GPU support to CodeProject.AI. From reading the docs it seemed super simple:
1. Install torch and torchvision via pip
2. use torch.backends.mps.is_available to test for MPS (Metal Performance Shaders)
3. set the torch device as "mps"
4. Bask in GPU awesomeness
Yeah, nah. It won't work out of the box.
First, PyTorch has M1 GPU support. Sort of, kind of. There's lots and lots of things that haven't yet been included, and it's a rapidly evolving library meaning you will want to include the nightly builds in your requirements.txt file (for PIP installs)
--pre
--force-reinstall
--extra-index-url https://download.pytorch.org/whl/nightly/cpu
torch
--pre
--force-reinstall
--extra-index-url https://download.pytorch.org/whl/nightly/cpu
torchvision
This allows PIP to use pre-release, it forces a reinstall to avoid caching, and it tells PIP where to find this magical nightly build version.
Second, Python is cross platform so if you only run the code on a machine where MPS has been included in the pytorch package you install, you're fine. The rest of the world needs something like
use_MPS = hasattr(torch.backends, "mps") and torch.backends.mps.is_available()
Third, you may need to adjust your code and force some things to use the CPU instead of the GPU. For example, currently TorchVision for Apple M1 doesn't support nms, so our YOLO code must be changed from
pred = non_max_suppression(pred, confidence, 0.45, classes=None, agnostic=False)[0]
to
pred = non_max_suppression(pred.cpu(), confidence, 0.45, classes=None, agnostic=False)[0]
The list of not-yet-supported methods is on GitHub[^]. If you have a fave issue go and vote for it.
So far I've seen a roughly doubling of performance for inference using the YOLOv5 model in CodeProject.AI, which is a nice boost for just a couple of hours of work. The changes are integrated into the 1.5.7.4 codebase of CodeProject.AI.
cheers
Chris Maunder
|
|
|
|
|
I feel like we're discussing how to install a fridge when all you want is a nice, cold beer but we're nothing without solid infrastructure.
In CodeProject.AI we support adding backend analysis modules in any language and tech stack, as long as that module can be installed (and uninstalled) neatly.
Python is obviously the biggest player in the AI space so supporting Python is critical. It's also tricky, and we rely on Python Virtual Environments to keep things clean. Clean-ish.
A Python Virtual Environment can lead one to think of a sandbox, or virtual machine where the environment is completely encased in a leak-proof container that protects it from interference from the outside, and protects the outside from harmful processes on the inside.
This isn't a Python Virtual Environment.
To create a a Python Virtual Environment for a given version of Python you must first have that version of Python installed in your environment. You run the command to create the a virtual environment (python -m venv) and what you get is a folder that contains a copy of, or symlink to, your original Python interpreter, as well as a folder to any Python packages you need to install into that a virtual environment.
This is your Python Virtual Environment.
The secret sauce is the "Activate" script which simply sets environment variables so that when you type "Python" at the command line, the Python interpreter inside your a Virtual Environment will be launched, not the system-wide version. Deactivate the Virtual Environment and the environment variables are reset, and your OS-default version of Python is now the default.
The details of this are not important.
The important part is that when you "activate" the virtual environment and then install packages via pip install, those packages will live inside the Virtual Environment's folder, and not inside the OS's global python package folder. This allows you to have different versions of the same package installed in different virtual environments.
Python installed in your OS with package A, package B
and also Python installed in Virtual Environment 1 with package A 2.0, package B
and also Python installed in Virtual Environment 2 with package A, package B 2.0
Installing Python in CodeProject.AI
When we install Python in a CodeProject.AI setup we either XCOPY in the Python executables (for Windows), or use apt-get or brew (Linux / macOS) to ensure we have a base Python installation, and then we create the Virtual Environment using the standard python -m venv and install the python packages.
But we do it like this:
"[PythonFolder]python.exe" -m venv "[PythonFolder]venv"
"[PythonFolder]venv\scripts\pip.exe" --no-cache-dir install -r requirements.txt --target "[PythonFolder]venv\Lib\site-packages"
Where [PythonFolder] is \src\AnalysisLayer\bin\Windows\Python37\ for Windows and Python 3.7
This calls the python interpreter and the pip utility from within the Virtual Environment directly, and ensures the output of these commands will also be within the Virtual Environment. No need to activate the Virtual Environment during this.
Even more importantly: You do not need to have Python or any Python tools setup on your machine for this to work. The whole point of our installer (and our dev installation scripts) is to allow you to be up and running with no prep. We do all that for you.
Using Python in CodeProject.AI
We create a virtual environment for each version of Python that we install. We still do not need to activate those environments. This is partly because we're calling the Python process from our server directly, and not from a command terminal. Calling a script to set environment variables prior to launching Python is a little cumbersome.
We could set the PATH variables directly, but we don't need to: we call the specific Python and Pip executables from the virtual environment using their full paths. On top of this, in our codeprojectAI.py module wrapper we add the path to the virtual environment's packages directory to sys.path in the code itself.
This means that
- The correct version of Python will be called
- The packages installed in the virtual environment will be used in preference to the packages installed globally
So there is no need to activate the Virtual Environment.
What we gain from this approach
We control the environment, we gain the flexibility of virtual environments, and we can add as many versions of python and as many combinations of installation packages as we need
What we lose from this approach
The biggest is size. Each Virtual Environment contains copies of packages probably installed elsewhere. PyTorhc, for instance, can be well over 1.3GB in size for the GPU enabled version. While size can be important, the size of Python modules will quickly pale in comparison to AI models, and even more so when one considers the data being input to these models. Video footage, for instance, gets really big, really fast.
The other downside is that modules installed in CodeProject.AI must use our module wrapper Python module to ensure the PATH is set correctly for the import statements to work, or they need to do that themselves. It's a small tradeoff given that using our SDK means 90% of the plumbing is done for you.
cheers
Chris Maunder
|
|
|
|
|
The only issue for us is the size of the models so we'll have to work out a simple way to allow you to pick and choose what, if anything, comes down the wire when you install. Still: this opens up a fun world of opportunities for us.
New release first thing next week.
cheers
Chris Maunder
|
|
|
|
|
Blue Iris Software has just announced the release of their first version that uses senseAI as their AI provider. This is very cool.
On top of that we've had word on senseAI and Agent DVR integration.
We'll be needing Custom model support and GPU support to ensure we can provide their end-users with the best experience possible. The timeline is within 2 weeks at the outside. Who needs sleep.
cheers
Chris Maunder
|
|
|
|
|
According to a recent StackOverflow survey 45% of developers use Windows, 25% macOS, and 71% use Visual Studio Code.
I've been trying, for years, to make a mac my primary machine and I've gone to many painful and frustrating lengths to get there. Except I've never quite got there.
I'm happy to announce, though, that as of tonight we have the senseAI development experience on Windows and macOS essentially on par (give or take the .NET WinForms demo app). If you live in VS Code you won't see any difference.
The caveat here is that we're talking macOS on Intel. macOS on Apple Silicon is a whole different bag of broken parts and we're still waiting for libraries such as the ONNX runtime to support Apple Silicon, and we still have issues with some .NET image libraries on the new chips.
Things will progress and with the release of the new M2 chips I'm sure everything will catch up sooner rather than later. It was announced just a few days ago that even Visual Studio 2022 would run natively on Arm64, meaning Visual Studio running in parallels on a new mac may now be an option for the times when one wants a little arm-chair style comfort in their development day.
cheers
Chris Maunder
|
|
|
|
|
We've just released senseAI v1.4.0 and we fell into the trap of "just one more thing" while working to get the release out.
Here's a timeline you've probably had yourself:
- We need to add feature X. Let's go!
- We hop on a Zoom call and start brainstorming ideas on how to do this.
- We settle on an idea and go for it
- One of us, deep in the bowels of the code, realises there's refactoring that could be done
- To release, then refactor, then re-release? Or refactor, since I'm here anyway, and then release?
And you know what happened. The urge to release the best code beat the urge to provide our users with new functionality.
Maybe we've been burned too many times by rushed releases. Visual Studio seems to be less and less stable and more and more bloated. Apple's iOS has an exciting history of chaos. CodeProject itself has broken things left, right, and centre more times than I care to remember.
But here's the issue with waiting till it's perfect.
It will never be perfect. We'll be lucky if it will be stable and useable. If we're really, really lucky it will be useful. That's simply the reality of software development.
So by holding off on releasing the code we ended up making the engine run smoother, a little faster, a little more efficient, but (to stretch the analogy) we're not letting anyone drive a perfectly functional car. And the purpose of writing software is to provide something your users can use. Hence the term. Users.
Having said here's a little more background to our decision.
The change we made, instead of releasing the code, was in the manner in which you add a module. One of the core pieces of senseAI is to make it easy for developers to integrate AI into their apps by taking wonderful Open Source projects and aggregating them into senseAI's environment. We make sure the runtime is sorted out, the packages are installed, the API is solid, the installer works, and developers just provide the fun stuff.
Our change was that we took a process that required maybe a little too much understanding of the mechanics of how it all works, and turned it into a process that required writing a single callback function. 240+ lines of reasonably complex code down to 65 lines of very straightforward code.
So our decision was wasn't "do we release new functionality" but rather "do we continue to encourage developers to use a painful way of adding modules when we know full well that in a week we'll have a much, much better way".
It's these sorts of decisions that have to be weighed against your users, your marketing objectives, your budget and your stakeholders. Maybe marketing needs something, anything to talk about. Maybe Marketing can't handle the complaints when poor release decisions are made. Maybe you need to demonstrate progress or maybe you need to know whether it's even worth continuing in a certain direction before even thinking about refactoring.
Development time is super, crazy expensive, so these decisions are important.
cheers
Chris Maunder
|
|
|
|
|
We're releasing a new version of SenseAI Server today and unfortunately we're still on Wix as the installer. Maybe it's grown on us, maybe it's just beaten us into submission.
A few highlights of this week
- When attempting to get a code signing certificate make sure your company's info is up to date. We've moved offices and our old address is everywhere. Our new one is, too, but unfortunately you don't get to pick and choose which sources of The Truth a cert vendor will use. Update your D&B info, and do it over the phone (via the web is all but useless if you're not a US company)
- When upgrading to Visual Studio 2022 don't burn your bridges. Our old webforms app didn't load. It didn't just "not load" it caused VS 2022 to throw an arithmetic overload exception. That's a bit dodgy. The issue?
<IISExpressSSLPort />
Evidently the project loaded was parsing the value under the IISExpressSSLPort node and must have done a int.Parse instead of a int.TryParse.
The other frustration is that all our menu, toolbar and environment customisations were not brought forward from 2019. Nor were many extensions. It's understandable that some would not be compatible (or needed) in 2022, but to not warn or offer compatible versions means a lot of re-setting up of your environment
- We've moved to .NET 6 entirely for SenseAI. .NET 5 has barely cooled on the racks but it's already so last week, so to make things neater for our dev work in Linux and macOS via VS Code, it's .NET 6 all the way. Which isn't supported by VS 2019, for no reason I can fathom. Well, apart from lots of marketing reasons, but actual, technical reasons that can't be surmounted? Nope, can't actually think of any, but then again I don't write IDEs. I just pay for them
cheers
Chris Maunder
|
|
|
|
|
We've officially given up on WiX. We tried, and succeeded, but it was not worth the pain, or the complexity, or the having to enable .NET 3.5.1, or the feeling that it's "by engineers, for engineers". We're engineers, and we (collectively, our entire industry) need to stop assuming that our end users have the time, patience, interest or understanding to deal with our output.
As an exercise I'm stepping back and looking at what we present to our users, and looking at each decision we're asking a user to make. The question on my mind is "Does making them choose improve the experience" and I'm learning that no, it often doesn't.
Providing a choice is often a way for a software developer to avoid making a choice themselves.
I'm not talking clear functional choices such as "Do you want coffee or tea?". I'm talking choices such as whether a message is entered as Markdown or HTML, whether you want a two column or three column layout, whether you want to use the built in Iris GPU or that Nvidia Beast 3000 I see over there. Makee thee call, based on the reason you wrote the app, and focus on backing that decision to the extent of your abilities.
If you're running around in circles adding code to satisfy 1% of your users, make sure those 1% of users are fundamentally important to the survival of your code, and not merely the 1% who contribute 90% of the complaints.
If you're also providing a choice simply because it's possible to provide a choice ask yourself whether that choice even makes sense. "Do you want this app to run smoothly and efficiently or do you want the version with 1 arm tied behind its back?" I'm sure there's a use case, somewhere, for the second option, but do you have the capacity to continue to support that use case at the expense of dev time on the main use case?
So for SenseAI we're switching to an installer that allows us to get more done with less fuss and with a far more gradual learning curve. Our SensaAI code is all open so our decisions around what installer we choose impacts how hard it is for someone to work with the codebase as a whole.
The less decisions we ask you, our end users and collaborators, to make means more time for you to explore and build.
cheers
Chris Maunder
|
|
|
|
|
We're finishing up our first version of an actual, real, grown up installer for SenseAI and it's been an interesting switch from deploying web applications to deploying an app on someone else's machine. Without being there. And trusting them to press the right button.
It's terrifying.
Here is our set of golden rules for installers
- It should be blindingly obvious where to download the installer.
We've all seen download pages that have "DOWNLOAD" ads strewn across them. That's just juvenile marketing and results in anger. We've also all seen (and I'm looking at you Python and Microsoft) pages that list 15 versions. And another couple of links for long term support, latest build, legacy support, current version, recommended version, and standalone version. It's like they don't actually want you to download.
So as few options as possible, preferably just one.
- The installer itself should not raise difficult questions.
Do you want to run this as a low priority background task on startup, or a Windows service? Should it be installed globally or locally? When installing should we use your built in Intel Iris graphics, or use the NVidia CUDA extensions or do you have an AMD graphics card with at least 4Gb RAM? I can imagine the look my father would be giving the installer.
Either reduce the questions to what you know is possible, or phrase them in sensible terms: "Do you want to save time or save money"?
- Allow the install to happen offline
When I travel home to see the family in Australia I'm usually saddled with terrible internet. 1Mb/sec with latency in the order of hours, it seems. I always update my laptop and phone before I leave and download anything I might need to install onto a thumbdrive just in case.
Alternatively, say you're installing something onto 3 machines and really don't want to (or can't) download 500Mb three times. If at all possible, provide at least the option of downloading the lot.
- Allow the install to be a minimum install
We at CodeProject generally prefer to suffer so our users don't have to. A little extra work our end in creating an installer that provides the means to choose what you wish to install before you download the big chunks is worth it. The Visual Studio installer, at 1Mb, is brilliant. Downloads in a second and then offers you the means to gorge on 20+ Gb of downloads, or something much leaner for those who don't need their system to be a cluttered basement.
- Provide all the features of an installer people expect. Progressing installation for when you want to add bits you didn't install previously. Updates when a new version comes out. Repairs for when your users accidently break stuff. And, of course, an uninstaller. An uninstaller that uninstalls cleanly.
And having said this our first installer won't have all these features. Progressive installs will be in the next version, and we're still debating on whether our first iteration will be a totally offline installer or a bootstrapper that pulls down the parts as needed. Again, both options will be in place as soon as possible.
Think about who will be installing your software and assume they don't understand the terms you use, don't have any time, and don't actually care. Software is a tool for doing other things. An installer is a tool for making something else that will do other things.
Our job is to allow people to do awesome stuff that may happen to include some of our tools at some point. They have better things to do than try and read our minds and/or become experts in our esoterica.
cheers
Chris Maunder
|
|
|
|
|
This is way overdue, but we've released CodeProject SenseAI Server.[^], Beta 1. Beta 2 is coming any day now, depending on Matthew's swearing and the amount of sleep I can get.
To back up a little:
At CodeProject we've been forever fascinated with the possibilities of AI. Dave has forever been the type of guy who will build, regardless of the technical obstacles, solutions that will make his life better. Matthew is up for anything as long as it involves learning and sharp, bleeding edges, and I'm addicted to data processing. Ryan (who is now Senior Content Strategist at ContentLab has a rich history in AI development and spent forever trying to get us up to speed with the latest trends and technologies in AI.
And we all found it insanely frustrating that at every step it was a mess of Terminal windows, hunting installers, reading the fine print, tweaking config files, ensuring you had just the right version of Python, except when you needed the other version of Python, and don't even get me started on library dependencies.
It often ended poorly so and we decided enough was enough and we would commit to creating a system that would allow the average developer - the one who's way too busy, with way too many things on their plate - to explore and have fun with and integrate AI into their programming life with zero fuss.
et voila.
SenseAI is a standalone server you can install anywhere. (caveat: "anywhere" currently means a Windows machine, but with Release 1, due in a week or so, it'll be Windows, Linux, macOS, and anything that will take our Docker image). The code is all there for you to grab and dig through, and will build and run under VS Code.
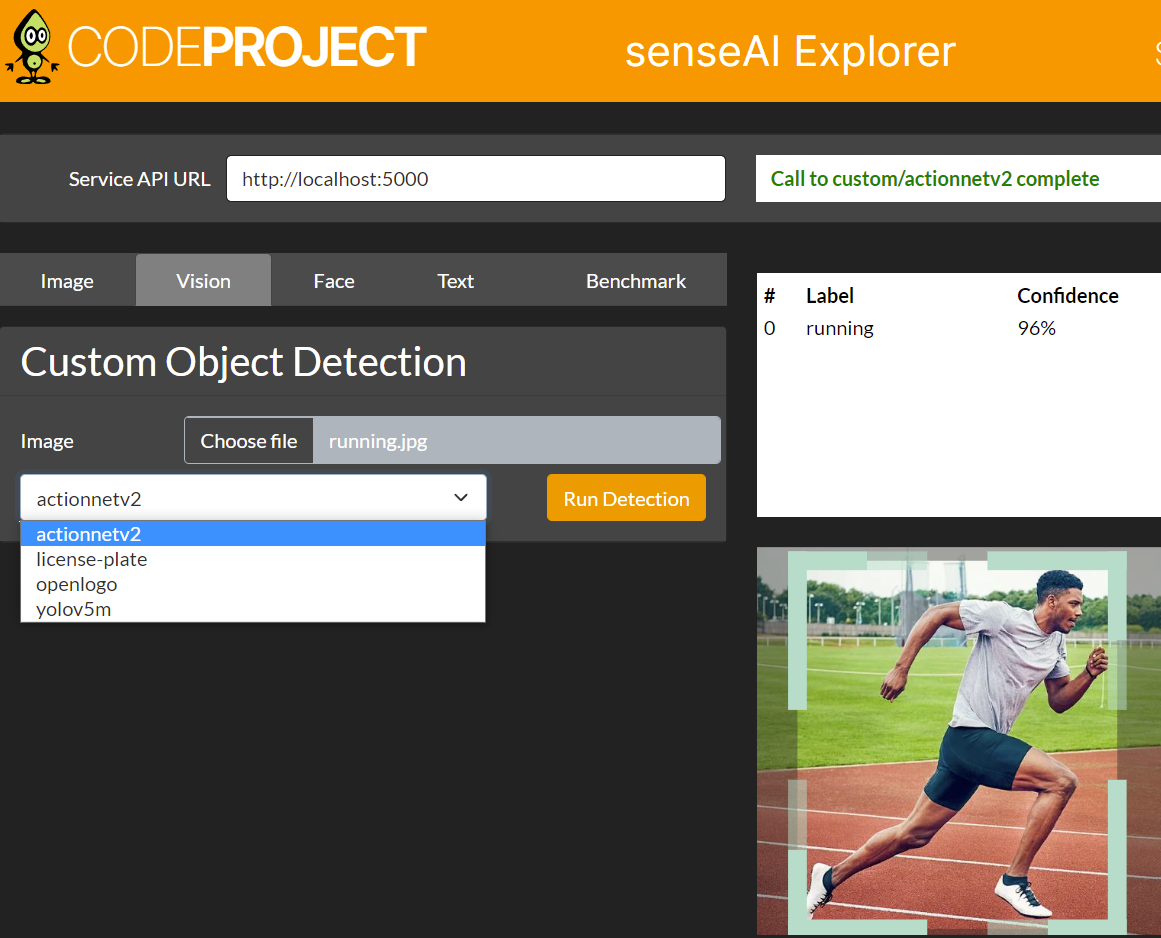
How it works is you install it on your machine, start it up, and you have a simple little AI server that will happily run analysis on any image you throw at it using a simple REST API. We've included a very simple HTML page that demo's the current features. Face detection and recognition, scene detection and object detection are the current capabilities, but we'll be continually adding new features as we find them.
And "find" is the important point here. Our goal isn't to write AI modules from scratch. There are way too many people far smarter than us who are very good at that stuff. Our goal is to aggregate the best open source projects, wrap it all up in a safe, tested, consistent, not-breaking-because-you-forgot-an-environment-variable, documented and supported service with a single API.
The architecture is simple: There's a front end server that handles the API calls. This is a lightweight .NET app. The backend is made up of a collection of independent modules. These modules typically handle one AI task (eg object detection, sound analysis, etc). When you send a request to the server that request finds it way to the correct module, which processes it, and sends the result back to the server, and from there back to the caller of the Server's API. Each module is totally independent, can be written in any language that can run in the environment, and can use it's own AI models. As the system evolves and we come across modules that are better, faster, smaller, or more accurate, we'll swap out the previous modules for the updated modules with no change in the API. You'll just see a little notification on your server's dashboard letting you know there is new goodness to be downloaded.
We'll be publishing examples of modules we've built and added to demonstrate how we'll be including new modules, and we'll also be providing a developer SDK in multiple languages to make communication between the included modules and the server simple.
We're starting small, we have lots of rough edges, but we're committed to building something awesome here. We hope you can join us and help out.
cheers
Chris Maunder
|
|
|
|
|
Each year we tally the reputation points earned by those who spend their time answering questions in Quick Answers and the forums, and by those who share their code and hard fought knowledge through articles and tips.
It's these developers who make this community what it is and each year I am again humbled at the generosity, the depth of talent, and the endless patience in helping those new to the craft, or just new to a particular technology.
A heartfelt thanks go to our new batch of CodeProject MVPs for 2022. The Most Valuable Experts for helping answer questions, and our Most Valuable Authors for their incredible articles.
Congratulations, and thank you, to the following:
| Most Valuable Expert | Most Valuable Author | | #realJSOP | #realJSOP | | Afzaal Ahmad Zeeshan | Abdulkader Helwan | | BillWoodruff | Christ Kennedy | | CHill60 | gggustafson | | Chris Copeland | Glenn Prince | | Christian Graus | Han Bo Sun | | CPallini | honey the codewitch | | Dave Kreskowiak | Jarek Szczegielniak | | Gerry Schmitz | Joel Ivory Johnson | | Greg Utas | Kenneth Haugland | | k5054 | Marc Clifton | | KarstenK | Marcelo Ricardo de Oliveira | | Luc Pattyn | Marijan Nikic | | Maciej Los | Matt Scarpino | | merano99 | Michael Haephrati | | OriginalGriff | Michael Sydney Balloni | | Patrice T | Mircea Neacsu | | phil.o | Mohammad Elsheimy | | Ralf Meier | Nick Polyak | | Richard Deeming | Pete O'Hanlon | | Richard MacCutchan | Peter Huber SG | | Rick York | raddevus | | RickZeeland | Raphael Mun | | Sandeep Mewara | Sergey Alexandrovich Kryukov | | Stefan_Lang | Sergey L. Gladkiy | | thatraja | Sergio Virahonda | | TheRealSteveJudge | Shao Voon Wong | | Tony Hill | Shaun C Curtis | | W∴ Balboos, GHB | Steffen Ploetz | | Wendelius | tugrulGtx |
cheers
Chris Maunder
|
|
|
|
|
As part of our Diving Into AI that we've been doing at CodeProject, we found ourselves with two issues.
- We didn't know Python anywhere near well enough
- We didn't like any of the current Python language references. And there are lots out there.
So we made our own! Sure, it's repeating, sort of, what's already out there, and sure, it was a convenient excuse for massive procrastination when we should have been doing real work, but it was fun, and we now have a reference that we like, and that suits our short attention spans.
Plus, we got to work with @Marc-Clifton on this who did lots of the heavy lifting.
Writing the reference also helped with #1. It forced us to understand the language at a much deeper level than merely reading examples, or formulaic tutorials. It also forces you into all the nooks and crannies of a language. And there are some odd nooks and crannies.
It's a work in progress, and presumably always will be. The URL is https://www.codeproject.com/ref/Python3, and please send us your suggestions, improvements, typos, rants, whatever.
cheers
Chris Maunder
|
|
|
|
|
It seems that the current state of AI is focused on the Scientists, not the Engineers. In other words, to use AI to do something like detect a package delivered to your front porch you need to understand Python, NumPy, Pandas, PyTorch, TorchVision, TensorFlow, Neural Networks and all the types of layers, Model Training, Transfer Learning, Calculus, Linear Regression, just to name a few.
To make matters worse, most of the books and articles I find seem to be geared to you getting advanced degrees in Math and Data Analysis.
I am an Engineer and Software Architect/Developer. I just want to pull in a package that either just works or helps me fall into the ‘Pit of Success’ while implementing the last mile. I do not want the users of my applications to have to suffer through complex and error prone installation and configuration. I do want easy configuration to tweak the application usage for specific optimizations for environments and use cases.
Granted, there are many repositories of Datasets, Neural Network implementations, Pre-Trained Models, but where is the tool that guides me in the selection of which to use for a particular use-case and hardware/OS combinations? Where is the package that provides or allows me easily to write a microservice for my Raspberry PI that, given a few if any pictures of raccoons, will signal my home automation system to turn on the sprinklers if a raccoon is on my garbage cans?
I have been looking at several open-source packages/repositories that attempt to tackle some aspect of this, but they are overly complex, difficult to build and test, huge, or lack extensibility.
As a result, I am looking at how I can leverage the vast collection of data, models, examples, and articles available and wrap up all the science into usable Lego® blocks to make using this amazing technology easy.
Stay tuned for ongoing progress reports, and the occasional rant, as we try and figure this out.
"Time flies like an arrow. Fruit flies like a banana."
|
|
|
|
|
I often say that JavaScript survived and dominated because it offend everyone less than its competitors did. It's ubiquitous. It runs everywhere. It's also a horrible mess of ridiculousness that sends developers insane.
But I loves JavaScript. It lets me be lazy and it lets me do totally stupid things and it forgives me and sometimes even works.
So speaking of ridiculous languages that thrive in spite of themselves, let's talk about Python. Python is like JavaScript in that it just kinda hung around trying to be useful in its own awkward way. It soon found itself being used as a scripting language, a teaching language, and a language you can slip on like a pair of sandals when you're rushed, with the same elegance and style therein. Type your code straight into the interpreter and bang, you're away.
This also made it great for Jupyter notebooks. And hacking together scripts to analyse data. And to perform operations on data. And to be the underpinning of the biggest paradigm change in computing, namely Artificial Intelligence.
See? The awkward introvert does come into his own eventually.
So we at CodeProject are finding ourselves surrounded by a sea of Python with no option but to hold our noses and jump right in.
As an ex-Environmental Engineer surrounded by FORTRAN writing physicists I still get the shivers when I see some of the Python code floating around. We can use more than 72 characters, guys, so please feel free not to name your variables x, y and z. But there's also a lot of amazing Python code out there. Incredible stuff.
This is the stuff we want to see more of so we're starting from basics and will be diving into Python, data analysis, and then some of the gnarlier Open Source Deep Learning and Artificial Intelligence packages available today. Our goal is to promote the knowledge of the field of AI but to do it by following the most treadworn path using Python. We're not trying to reinvent anything: rather, we want to present it back to the community in a form that's easily digested.
Right now we're most of the way through our initial offering which is the most basic Python Reference we could conceive. Short, code-first, simple examples, and an emphasis on explaining "why" instead of "what".
It'll be a work in progress but we hope to have the first version live before Halloween.
While you're waiting, make sure you be awesome when you code.
cheers
Chris Maunder
|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin