Big Data
As the name implies, Big Data is the huge amount of data which is complex and difficult to store, maintain or access in regular file system using traditional data processing applications. And what are the sources of this huge set of data.
- A typical large stock exchange
- Mobile phones
- Video sharing portal like YouTube, Vimeo, Dailymotion, etc.
- Social networks like Facebook, Twitter, LinkedIn, etc.
- Network sensors
- Web pages, text and documents
- Web logs
- System logs
- Search index data
- CCTV images
Data Types
Data can be identified as the following three types:
- Structured Data: Data which is presented in a tabular format and stores in RDMS (Relational Database Management System)
- Semi-structured Data: Data which does not have a formal data model and stores in XML, JSON, etc.
- Unstructured Data: Data which does not have a pre-defined data model like video, audio, image, text, web logs, system logs, etc.
Characteristics of Big Data Technology
A regular file system with typical data processing application faces the following challenges:
- Volume – The volume of data coming from different sources is high and potentially increasing day by day
- Velocity – A single processor, limited RAM and limited storage based system is not enough to process this high volume of data
- Variety – Data coming from different sources varies
And therefore, the Big Data Technology comes into the picture:
- It helps to store, manage and process high volume and variety of data in cost & time effective manner.
- It analyzes data in its native form, which could be unstructured, structured or streaming.
- It captures data from live events in real time.
- It has a very well defined and strong system failure mechanism which provides high-availability. It handles system uptime and downtime:
- Using commodity hardware for data storage and analysis
- Maintain multiple copies of the same data across clusters
- It stores data in blocks in different machines and then merges them on demand.
Hadoop
Hadoop is a platform or framework which helps to store high volume and variety of data in single or distributed file storage. It's open source, programmed in Java and distributed by Apache Foundation. It has a distributed filesystem called HDFS (Hadoop Distributed File System) which enables storing & fast data transfer among distributed file storages and MapReduce to process the data.
So, Hadoop has two main components:
- HDFS is a specially designed file system to store and transfer of data among parallel servers using streaming access pattern.
- MapReduce to process data.
Hadoop Hardware Architecture
There are some key terms that need to be understood:
- Commodity Hardware: PCs/Servers uses cheap hardware can be used to make clusters.
- Cluster: A set of commodity PCs/Servers interconnected in a network
- Node: Each of the commodity PCs/Servers is called node.
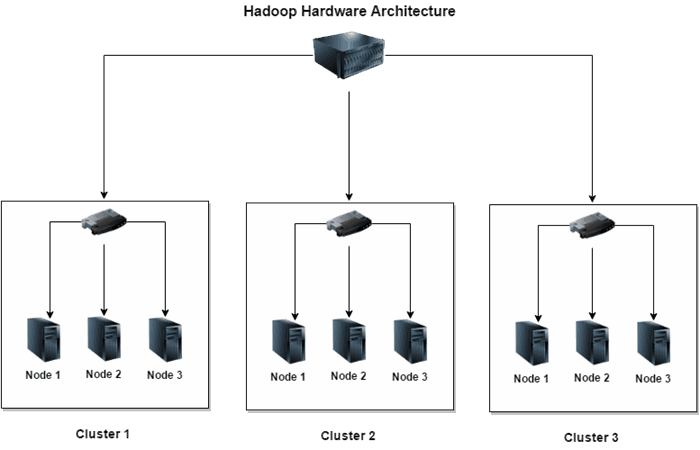
So, Hadoop supports the concept of distributed architecture. The above diagram shows how a set of interconnected nodes makes clusters and how the clusters are interconnected through Hadoop framework.
- The number of nodes in each cluster depends on the network speed
- Uplink from cluster to node is 3 to 4 Gb/s
- Uplink from cluster to cluster is 1 GB/s
HDFS vs Regular File System
| Regular File System | Hadoop Distributed File System |
| The size of each data block is small like 4KB
| The size of each data block is 64 MB or 120 MB
|
| If a 2KB file is stored in one block, the remaining 2 KB is unused or wasted
| If a file of 50 MB is stored in one block, the remaining 14 MB can be used
|
| Slow access to blocks
| Provides high-throughput access to data blocks
|
| Large data access suffers from disk I/O problems, mainly because of multiple seek operation
| Reads huge data sequentially after a single seek
|
| Provides fancy and user friendly interface for managing the file system
| Provides limited interface for managing the file system
|
| Creates only one copy of each data block. If the data block is erased, the data is lost
| Creates 3 replicas of each data block by default and distributes them on computers throughout the clusters to enable reliable and rapid data access
|
- HDFS exposes a specially designed file system on top of OS defined file system.
- It facilitates the user to store data in files.
- It maintains Hierarchical file system with directories and files.
- HDFS supports different file I/O operations like create, delete, rename, move, etc.
Hadoop Core Services
Hadoop follows Master-Slave architecture. There are 5 services run in Hadoop:
NameNodeSecondary NameNodeJobTrackerDataNodeTaskTracker
NameNode, Secondary NameNode and JobTracker are called master services and DataNode and TaskTracker are called slave services.
As the diagram denotes, each of the master services can talk to each other and each of the slave services can talk to each other. Since DataNode is a slave service of NameNode, they can talk to each other and TaskTracker is a slave service of JobTracker, they can also talk to each other.

HDFS Operation Principle
The HDFS components comprise different servers like NameNode, DataNode and Secondary NameNode.
NameNode Server
NameNode server is a single instance server which is responsible for the following:
- Maintain the file system namespace
NameNode behaves like table of content of a book. It knows the location of each block of data.- Manage the files and directories in file system hierarchy.
- It uses a file called
FsImage to store the entire file system namespace including mapping of blocks to file and file system properties. This file is stored in NameNode server’s local file system. - It uses a transaction log called
EditLog to record every change that occurs to the file system meta data. This file is stored in NameNode server’s local file system. - If there is any I/O operation occurs in HDFS, the Meta Data files of
NameNode server is updated. - Meta Data files are loaded into Memory of
NameNode server. Whenever there is a new DataNode server joined to the cluster, the Meta Data files in memory are updated and then keep an image of the files in local file system as checkpoint. - The
Metadata size is limited to the RAM available in NameNode server. NameNode is a critical one point of failure. If it fails, the entire cluster will fail.- But the
NameNode server can partially be restored from a secondary namenode server.
DataNode Server
There could be any number of DataNode servers in a cluster depending on type of network and storage system in place. It is responsible for the following:
- Store and maintain the data blocks
- Report to
NameNode server periodically to update meta data information - Store and retrieve the blocks when there is a request comes from client or
NameNode server - Execute read, write requests, performs block creation, deletion and replication upon instruction from
NameNode - Each of the
DataNode servers sends Heartbeat and BlockReport to NameNode server in specific duration. - If any
DataNode server does not report to NameNode server in specific duration, NameNode server thinks this DataNode server as dead and remove the metadata information of that DataNode server.
Secondary NameNode Server
There could be a single instance of Secondary NameNode server. It is responsible for the following:
- Maintain a backup of
NameNode server - It’s not treated as a disaster recovery of
NameNode server but the NameNode server can partially be restored from this server. - Keeps namespace image through edit log periodically
When a client request Hadoop to store a file, the request goes to NameNode server. For example, the file size is 300 MB. Since the size of each data block is 64MB, the file will be divided into 5 chunks of data blocks where 4 of them equals 64 MB and the 5th one is 44MB and stores them in 5 different data node servers within same cluster with 3 replicas. Here, the chunks of data are called inputsplit. NameNode service then keep the information like where the data blocks are stored, how much is the block size, etc. This information is called meta data.
Here is the complete flow of the operation:
- The file is divided into 5 inputsplit say a.jpg, b.jpg, c.jpg, d.jpg and e.jpg and the original file name is photo.jpg and file size 300 MB
- The client sends request to
NameNode server with this details asking what are the DataNode Servers has available data blocks to store them. NameNode server respond to client with the details of DataNode servers which has enough space to store the file. Let’s say it sends the following details:
| InputSplit | DataNode Server |
| a.jpg
| Data Node Server 1
|
| b.jpg
| Data Node Server 3
|
| c.jpg
| Data Node Server 5
|
| d.jpg
| Data Node Server 6
|
| e.jpg
| Data Node Server 7
|
- Once the client receives response from
NameNode server, it starts requesting the DataNode servers to store the file. It starts sending the first inputsplit a.jpg to DataNode server 1. - Once the
DataNode Server 1 receives the request, it stores a.jpg in its local file system and request replication to DataNode Server 3. - Once the
DataNode Server 3 receives the request, it stores a.jpg in its local file system and request another replication to DataNode Server 7. - Once the
DataNode Server 7 receives the request, it stores a.jpg in its local file system and send acknowledgement back to DataNode Server 3 saying that the file has been stored properly. DataNode Server 3 then send acknowledgement back to DataNode Server 1 saying that the file has been properly replicated in DataNode Server 3 & 5DataNode Server 1 then send acknowledgement back to the client saying that the file has been stored and replicated properly.DataNode Server 1, 3 & 5 send BlockReport to NameNode server to update metadata information.- The same process repeats for the other inputsplits.
- If any of the
DataNode server 1, 3 & 5 stops sending Heartbeat and BlockReport, NameNode server thinks that the DataNode server is dead and choose another DataNode server to replace the replication of the a.jpg inputsplit. - There should be a program written in Java or any other language to process the file photo.jpg. The client sends this program to
JobTracker component of Hadoop. The JobTracker component gets the meta data information from NameNode server and then communicates with TaskTracker components of the respective DataNode servers to process the file. The communication between JobTracker and TaskTracker is called Map. The number of inputslits in DataNode servers equals the number of Mapper. In the above example, there will be 5 mappers running to process photo.jpg file. - The
TaskTracker components keep reporting to JobTracker component if they are processing the request properly or are they alive. If there is any TaskTracker stops reporting to JobTracker, the JobTracker assigns the same task to one of the TaskTrackers where the replications of the inputslipt are stored. - The
JobTracker assigns tasks to TaskTracker depending on how close the TaskTracker is and how many mappers are running. - Each
Mapper produces one output file for every task assigned. In this example, there will be 5 mappers producing 5 different output files. There will be a Reducer who will combine these 5 input files and report to the DataNode server where the Reducer is running, DataNode Server 4 for example. The DataNode Server 4 will then communicate with NameNode server by providing meta data saying that there is one out file called output.jpg has been processed and ready to use. - Client will keep watching and communicate with
NameNode server once the processing is completed 100% and output.jpg file is generated. NameNode server response back to client saying that the file has been processed and ready to use in DataNode Server 4. - Client then sends request to
DataNode Server 4 directly and get the output.jpg file
Conclusion
Hope you enjoyed reading it and have learnt something new. In my next consecutive articles, I will show you how to install Hadoop and explain different components of Hadoop in details.
Thanks for reading my article and keep in touch.
History
- 22nd January, 2017: Initial version
I am Bachelor in CSE from Khulna University of Engineering & Technology,Bangladesh. I have more than 11 years experience in software design & development, data analysis & modeling, project management and currently working in a software company in Dubai,UAE as a Lead Software Engineer. I am MCAD(Microsoft Certified Application Developer) certified since 2005. Please feel free to contact with me at nill_akash_7@yahoo.com.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





