Series Links
Table Of Contents
It has been a while since I wrote an article, but I thought what better way to start 2016 then to write an article.
This article is the 1st of a 2 part (proposed) article series. The series will show you how to use 2 awesome bits of technology together. Namely Apache Cassandra and Apache Spark.
This article will talk you through how to get Apache Cassandra up and running as a single node installation (ideal for playing with). Whilst the next article will build upon a previous article I wrote about Apache Spark, and will teach you how to use Cassandra and Spark together.
Since I wrote about Apache Spark before (http://www.codeproject.com/Articles/1023037/Introduction-to-Apache-Spark), I am simply going to reiterate what I said in that article. It is that article I will be using to modify to get it to interact with Cassandra.
This is what the creators of Apache Spark have to say about their own work.
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
http://spark.apache.org/docs/latest/index.html up on date 20/01/2016
mmm want a bit more than just that, try this
At a high level, every Spark application consists of a driver program that runs the users main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.
A second abstraction in Spark is shared variables that can be used in parallel operations. By default, when Spark runs a function in parallel as a set of tasks on different nodes, it ships a copy of each variable used in the function to each task. Sometimes, a variable needs to be shared across tasks, or between tasks and the driver program. Spark supports two types of shared variables: broadcast variables, which can be used to cache a value in memory on all nodes, and accumulators, which are variables that are only available to, such as counters and sums.
Spark programming guide up on date 24/08/15
If you are the sort that likes diagrams, here is one that may help
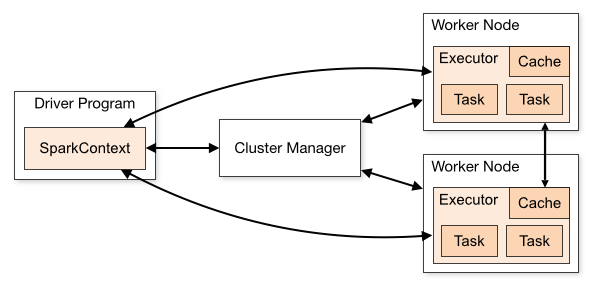
So that is what they have to say about it. Here are a couple of my own bullet points that may also help:
- Spark provides a common abstraction : Resilient Distributed Datasets (RDDs)
- Spark provides a LINQ like syntax that you can actually distribute across multiple worker nodes (LINQ like syntax across multiple nodes, think about that for a minute, that is like um WOW)
- Spark provides fault tolerance
- Spark provides same API for running locally as it does within a cluster which makes trying things out very easy
- Spark provides fairly simple API
- Very active community
- Put bluntly, It is a bloody brilliant product
The following diagram illustrates the current Apache Spark offering. Each one of the dark blue blocks in the diagram are a slightly different offering, for example:
- Spark SQL : Allows querying of structure data, such as JSON into RDDs (which means you can run RDD operations on JSON effectively)
- Spark Streaming : Allows the micro batching of data over time (window buffer, size buffer, sliding buffer etc. etc.), where the data received in that buffer is presented as a list. Which makes it very easy to deal with. Spark Streaming has many sources, such as
- Sockets
- Kafka
- Flume
- Zero MQ

Under pinning all of these is the common abstraction (Resilient Distributed Datasets (RDDs). So let's carry on and talk a but more about RDDs.
This is what the creators of Cassandra say (see http://cassandra.apache.org/up on date 20/01/2016)
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra's support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
Cassandra's data model offers the convenience of column indexes with the performance of log-structured updates, strong support for denormalization and materialized views, and powerful built-in caching.
Proven
Cassandra is in use at Constant Contact, CERN, Comcast, eBay, GitHub, GoDaddy, Hulu, Instagram, Intuit, Netflix, Reddit, The Weather Channel, and over 1500 more companies that have large, active data sets.
One of the largest production deployments is Apple's, with over 75,000 nodes storing over 10 PB of data. Other large Cassandra installations include Netflix (2,500 nodes, 420 TB, over 1 trillion requests per day), Chinese search engine Easou (270 nodes, 300 TB, over 800 million requests per day), and eBay (over 100 nodes, 250 TB).
Fault Tolerant
Data is automatically replicated to multiple nodes for fault-tolerance. Replication across multiple data centers is supported. Failed nodes can be replaced with no downtime.
Performant
Cassandra consistently outperforms popular NoSQL alternatives in benchmarks and real applications, primarily because of fundamental architectural choices.
Decentralized
There are no single points of failure. There are no network bottlenecks. Every node in the cluster is identical.
Durable
Cassandra is suitable for applications that can't afford to lose data, even when an entire data center goes down.
You're in Control
Choose between synchronous or asynchronous replication for each update. Highly available asynchronous operations are optimized with features like Hinted Handoff and Read Repair.
Elastic
Read and write throughput both increase linearly as new machines are added, with no downtime or interruption to applications.
So that is the sales pitch, but what does it do?
Well I will use my own words here, so please shoot me down if you are a Cassandra veteran and reading this and think hang on a minute that is just pure BS.
Cassandra has its foot in a couple of camps, it supports NoSQL, and native JSON support is coming very soon. So that is one thing, but it much more than that, it runs in a fault tolerant cluster with replication across nodes within the cluster, so its durable. It also has the concept of a nominated master (who could be usurped by another should the master falter).
These are all awesome things, but what is cool about Cassandra is that is essentially a distributed hash table, where each node in the "ring" will hold tokens (Partition Keys).
This figure may help to illustrate this:
CLICK FOR BIGGER IMAGE
This enabled ultra fast lookups, providing you have your model right, which is also one of the reasons why Cassandra is a bit fussy about what type of queries you write. If you have petabytes of data you would NOT want to it every node to get that data. Cassandra tries to help you out here, and not let you do unbounded queries.
Data modeling techniques using Cassandra are a bit out of scope for this article, but if that sort of stuff interests you, you should od this free course : https://academy.datastax.com/courses/ds220-data-modeling
Another great thing about Cassandra is the gossip protocol it used to ensure that nodes know about each other and their state. You can read more about this here : http://docs.datastax.com/en/cassandra/2.0/cassandra/architecture/architectureGossipAbout_c.html
Now this is all awesome news, but does using Cassandra comes with any draw back, sure it does:
- You cant just bang out a Cassandra installation, it needs to be thought out well, and modeled extremely well
- There is NO real ORM support
- There is the concept of CAP theorem, which is as follows, which you dictates you can have 2 of the 3 sides of the triangle, you must make peace with this:
CLICK FOR BIGGER IMAGE
As can be seen above Cassandra is in the A/P camp.
Ok so if you got this far you must be interested enough to find out a bit more. So just why would you use Apache Spark and Apache Cassandra together? Lets pause and think about that for a minute. I have already stated that the typical setup for both of these tools is to run in a cluster. Now what if we use the same machines to run both Spark + Cassandra. That is each machine in the cluster would be running both Spark + Cassandra.
Interesting. Would you do this in real life. Yep for sure. There are actually a couple of really good reasons to run this setup.
- Spark RDD results can be stored to disk just using Spark, but if you introduce a database (i.e. Cassandra) into the mix, we could do all sorts of things with those results, like reporting, transformations etc. etc.
- Data locality. This takes advantage of the fact that you may end up running a cluster where you have a Spark node and Cassandra node on the same physical box. Data will be more easily accessible, the spark/Cassandra driver has some smarts which makes use of data locality
This section will walk you through how to install Cassandra locally on a Windows machine. This will be a single node Cassandra install, which is not what you would use in production, but for playing around with and for messing about with Apache Spark, it is enough for you to get the concepts.
You MUST ensure you have the following thing installed before you carry on with the rest of this articles setup
am primarily a Windows user, and for experimenting with things I typically just try and do the simplest thing possible which for Cassandra means installing the DataStax Community Edition (which is free), and is very easy way to try out Cassandra, on a stand alone machine.
You would OBVIOUSLY NOT do this for a real setup, you would use a cluster of machines running Linux to host the Cassandra instances.
In fact one way to do that pretty quickly on your own Windows PC is to use Vagrant the virtual machine image software to quickly spin up a cluster.
There are some nice ones here:
If you have not heard of Vagrant, you should read more about that here : https://www.vagrantup.com/
Anyway we digress, we want to set up a single node instance on Windows (for simplicity).
Grab the DataStax community edition from here : http://www.planetcassandra.org/cassandra/. I went for the 64 bit version MSI, where I just grabbed the latest version of the MSI.
I simply followed the MSI installer, and made sure that the OpsCenter is set to start automatically.
There are some good instructions/screen shots of this entire process here :
http://www.datastax.com/2012/01/getting-started-with-apache-cassandra-on-windows-the-easy-way
When you install the DataStax community edition, you get a couple of cool things
- CqlSh is installed for you, which you can launch using the "Cassandra CQL Shell" which when run should give you something like this:
CLICK FOR BIGGER IMAGE
CLICK FOR BIGGER IMAGE
- The ability to start and stop services for Cassandra / OpsCenter
CLICK FOR BIGGER IMAGE
Now that have installed a very simple/low touch Cassandra installation (remember this is to play with ONLY, we would not do this for real, we would create a cluster on Linux), its time to add the ability to query our Cassandra installation.
There are 2 tools for this Cqlsh, the CQL scripting host, a command line utility. It is ok, but if you are just starting out you probably want something more visual.
Luckily there is another DataStax tool available called dev center, which you can download from here:
https://academy.datastax.com/downloads/ops-center?destination=downloads/ops-center&dxt=DevCenter#devCenter
Make sure you download the version of this that matches your Java installation. For example I am running the 64 bit version of Java, so I needed to grab the 64 Bit Dev Center installation. Failure to observe this advise will more than likely mean that DevCenter.exe will not run correctly.
This tool is a bit like SQL Server Enterprise Manager, though a lot less rich in scope, and it uses a lot of RAM to run, which is odd as its not doing that much if you ask me.
So once you have downloaded the CORRECT version of the DataStax DevCenter you will have a zip file, for me this was called "DevCenter-1.5.0-win-x86_64.zip". So simply unzip that somewhere.
So once you have unzipped the downloaded zip, you should see something like this:
So now that we have that unzipped we should be able to run the app by clicking the DevCenter.exe icon. Doing that should run the app, which if running correctly should look like this:
C LICK FOR BIGGER IMAGE
Note that there is no active connection yet. We will be setting up a connection in the next step.
Ok so let's recap of what we have done so far:
- You have installed Java JRE if you did not have it installed already
- You have installed Java JDK if you did not have in installed already
- We obtained and installed the DataStax community edition (with a sly nod that we would NOT do this for production, we would be good chaps/chapesses and set up a nice Linux cluster)
- We obtained and unzipped the DataStax DevCenter
- We ran DataStax DevCenter
All good stuff, but we need to test that Cassandra installation. So lets do that.
Let's launch the DevCenter again. And let's create a new connection, it is as easy as following along with these screen shots. I should just point out that my laptop has a QHD resolution, and that it why the screen shot buttons look weird. This is what the app looks like when you have a modern good laptop. Doh. Loads of apps are like this for me, Doh * 2.
Click on the new connection button
CLICK FOR BIGGER IMAGE
Fill in the local host address and then click the "Add" button
CLICK FOR BIGGER IMAGE
Just finish the wizard
CLICK FOR BIGGER IMAGE
Right click on the new connection, and choose to "Open Connection"
Then use the File -> New -> Keyspace menu item
CLICK FOR BIGGER IMAGE
Give the keyspace a name
CLICK FOR BIGGER IMAGE
I chose to script it to a new window, so we could run it from the DevCenter
CLICK FOR BIGGER IMAGE
Run it from DevCenter
CLICK FOR BIGGER IMAGE
If all ok we should see a new KeySpace in the list
If you got to this final step, you have a successful Cassandra installation. Well Done.
Next time we will be using a small Apache Spark demo project that I previously wrote, and we will modify that to load/save data from Apache Cassandra.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




