Here we look at a brief history of machine translation, and SMT.
Introduction
Google Translate works so well, it often seems like magic. But it’s not magic — it’s deep learning!
In this series of articles, we’ll show you how to use deep learning to create an automatic translation system. This series can be viewed as a step-by-step tutorial that helps you understand and build a neuronal machine translation.
This series assumes that you are familiar with the concepts of machine learning: model training, supervised learning, neural networks, as well as artificial neurons, layers, and backpropagation.
Before diving into specifics of the use of deep learning (DL) for translation, let’s have a quick look at machine translation (MT) in general.
Brief History of Machine Translation
The concept of MT, or the ability to automatically — using a machine — translate texts from one natural language to another dates back to 1949, when Warren Weaver formulated the main MT principles . At first, MT was done using expert rules (RBMT), which required a lot of work by human translators. Then, in the late 1970s, statistical machine translation (SMT) emerged and quickly flourished, especially with the help from the Candide project funded by IBM.
SMT was based on computation of the most probable relationship between pairs of words and sentences taken from the text corpora (in the original language and the target language). SMT ruled in the MT domain until the year 2000, when the application of neural networks to MT — neural machine translation (NMT) — was proposed as an alternative.
While NMT did not succeed at the beginning, it made impressive progress over the years. With the recent growth of AI processing power (GPU cards, among other examples) NMT has started to deliver results superior to SMT’s.
With the ongoing research on DL and long short-term memory (LSTM) designs, NMT is getting more and more mind-blowing results; it’s likely only a matter of time before NMT replaces most SMT in commercial translation software.
Deep Learning is good at MT because it aims to create an artificial brain. Theoretically, everything a human brain can do, a DL system can do as well. Besides, LSTM — a DL technique or, to be more precise, a recurrent neural network (RNN) — has an unprecedented record of recalling and detecting temporal patterns. This is exceptionally useful when considering a natural language sentence as a conditional time series of words, or as a result of a Markov process.
How does LSTM Network Handle MT
SMT in a Nutshell
Let’s focus on how our LSTM will work in the MT context, starting with a brief description of the main principles of SMT.
The functionality is based on a parallel corpus. This is, in essence, a "super-dictionary" — typically sourced from professional translators or senior students — that matches pairs of words or sentences in two languages.
Both SMT and NMT use parallel corpus. SMT partitions the input sentence into groups of words, and then uses probabilities to find the most probable matching combination.
An SMT, such as Moses, will create a translation model from the training data and apply that model to any input. The result is the sentence in the target language that has the highest score in terms of conditional probability.
Many sources on the internet offer parallel corpus for natural languages. Great examples include sites like the Tatoeba project and Linguee.
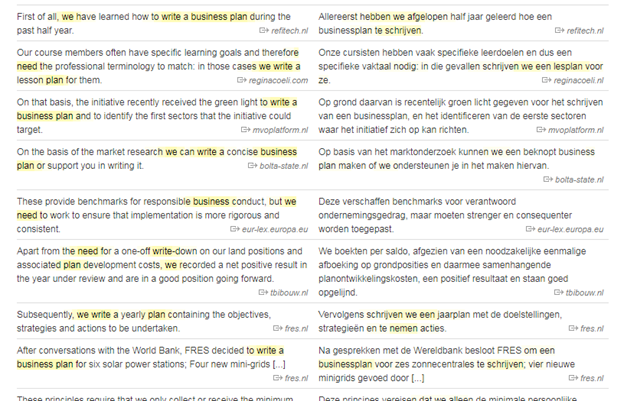
parallel corpus from the Linguee.com website.
The Tatoeba project provides tab-delimited bilingual sequence pairs for the various languages. For instance, the English/Dutch parallel corpus contains about 50,000 lines of translated pairs.

parallel corpus (English/Dutch) from the Tatoeba project.
Usually SMT will create a language model for the non-parallel corpus of the input language.
The translation model and the language model are then used, possibly along with a lexicon model and an alignment model, to compute a series of probabilities using the bayesian rules and the maximal likelihood (MLE) estimator. The MLE scores the options, and the MT picks up the sentence in the targeted language with the highest MLE score. In other words, it picks up the one that matches the input sentence best. By computing the conditional probabilities, estimators such as the MLE score candidates for the translated sentence.
Next Steps
Now that we've taken a quick look at the history of AI language translation and have a high-level understanding of how it works, it's time to dive into the gritty details. The next article in the series is a bit academic, but it'll be very helpful in developing an intuitive understanding of how AI translation works.
If you'd prefer to just go straight to the code so you can start creating your own translation model, that's okay too! In that case, you can safely jump to Tools for Building AI Language Automatic Translation Systems.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





